
Event streams are similar to digital root systems in business, capturing real-time data from multiple sources for further processing and analysis.
Event Streaming is Used For?
Event streaming is used in a variety of industries for payments, logistics tracking, IoT data analytics, customer communication, healthcare analytics, data integration, and more

Apache Kafka is an event streaming platform. What does that mean?
- Kafka allows you to publish and subscribe to event streams.
- It preserves these streams reliably for as long as necessary.
- You can process streams in real time or in retroactively.
- Kafka is distributed, scalable, fault tolerant, and secure.
- It works across platforms and can be monitored or fully managed by vendors.
[Good Read: Kubernetes Security ]
How does Kafka work?
Kafka is a distributed system with servers and clients communicating via high-performance TCP. It can run on various platforms like bare-metal, VMs, or containers in on-premise or cloud setups.
- Servers: Form a cluster across datacenters or cloud regions, with some acting as brokers for storage.
- Clients: Enable building distributed apps and microservices to read, write, and process events at scale, even handling faults or network issues.
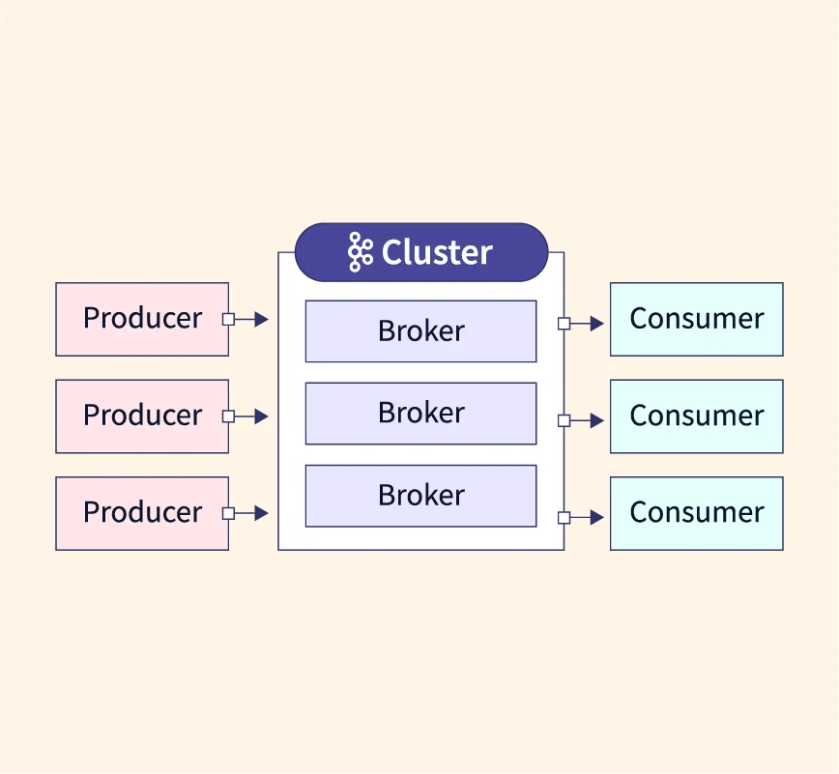
- Broker: A server running Kafka that connects different services.
- Event: Messages in Kafka stored as bytes on the broker’s disk.
- Producer and Consumer: Services that send or receive events in Kafka.
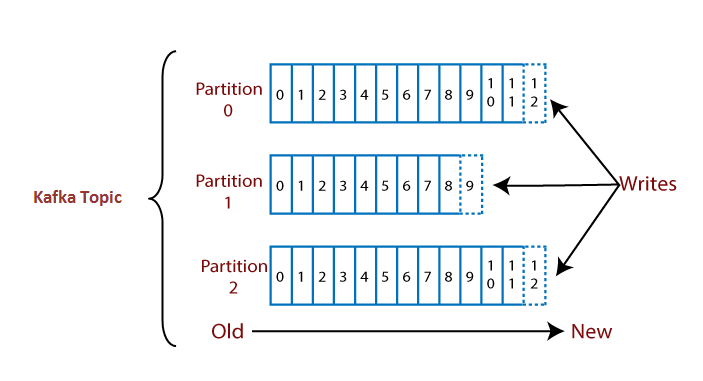
- Topic: A way to categorize events, like folders in a file system.
- Partition: Parts of a topic used to handle data more efficiently.
- Replication Factor: Copies of partitions for backup in the Kafka cluster.
- Offset: Tracks which events a consumer has already read . A producer producing messages to a kafka topic with 3 partitions would look like this:
- Zookeeper: Manages Kafka cluster status, permissions, and offsets.
- Consumer Group: A group of consumers that work together to read from topics.
Configuring a Kafka production-ready cluster
Step-1 Add strimzi repo and install strimzi-operator by using helm
Step-2 Configuring kafka cluster
helm repo add strimzi https://strimzi.io/charts/
helm install strimzi-operator strimzi/strimzi-kafka-operator -n kafka
Here node affinity is used to run all kafka pods on a specific node pool.
kafka-cluster.yaml
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
namespace: kafka
labels:
app: kafka
environment: prod-lke
spec:
kafka:
version: 3.6.1
replicas: 3
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: tls
port: 9093
type: internal
tls: false
- name: external
port: 9094
type: loadbalancer
tls: false
authentication:
type: scram-sha-512
resources:
requests:
memory: "16Gi"
cpu: "2"
limits:
memory: "16Gi"
cpu: "4"
template:
podDisruptionBudget:
maxUnavailable: 0
pod:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: lke.linode.com/pool-id
operator: In
values:
- "238182"
tolerations:
- key: "kubernetes.azure.com/scalesetpriority"
operator: "Equal"
value: "spot"
effect: "NoSchedule"
config:
default.replication.factor: 3
min.insync.replicas: 2
offsets.topic.replication.factor: 3
transaction.state.log.min.isr: 2
transaction.state.log.replication.factor: 3
zookeeper.connection.timeout.ms: 6000
jmxOptions: {}
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 25Gi
deleteClaim: false
class: linode-block-storage-retain
zookeeper:
replicas: 3
storage:
type: persistent-claim
size: 25Gi
class: linode-block-storage-retain
deleteClaim: false
resources:
requests:
memory: "4Gi"
cpu: "1"
limits:
memory: "4Gi"
cpu: "2"
jvmOptions:
-Xms: 2048m
-Xmx: 2048m
template:
podDisruptionBudget:
maxUnavailable: 0
pod:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: lke.linode.com/pool-id
operator: In
values:
- "238182"
entityOperator:
topicOperator:
resources:
requests:
memory: "256Mi"
cpu: "200m"
limits:
memory: "256Mi"
cpu: "1"
userOperator:
resources:
requests:
memory: "512Mi"
cpu: "200m"
limits:
memory: "512Mi"
cpu: "1"
template:
pod:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: lke.linode.com/pool-id
operator: In
values:
- "238182"
kubectl apply -f kafka-cluster.yaml -n kafkastep:3 – Kafka-ui monitoring tool is deployed which gives more insights about your kafka cluster.
kafka-ui.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kafka-ui-deployment
labels:
app: kafka-ui
spec:
replicas: 1
selector:
matchLabels:
app: kafka-ui
template:
metadata:
labels:
app: kafka-ui
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: lke.linode.com/pool-id
operator: In
values:
- "238182"
containers:
- name: kafka-ui
image: provectuslabs/kafka-ui:latest
env:
- name: KAFKA_CLUSTERS_0_NAME
value: "my-cluster"
- name: KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS
value: my-cluster-kafka-bootstrap.kafka.svc:9092
- name: AUTH_TYPE
value: "LOGIN_FORM"
- name: SPRING_SECURITY_USER_NAME
value: "admin"
- name: SPRING_SECURITY_USER_PASSWORD
value: "pass"
imagePullPolicy: Always
resources:
requests:
memory: "256Mi"
cpu: "100m"
limits:
memory: "1024Mi"
cpu: "1000m"
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: kafka-ui-service
spec:
selector:
app: kafka-ui
ports:
- protocol: TCP
port: 8080
type: LoadBalancer
kubectl apply -f kafka-ui.yaml -n kafkaOutput of the above files after applying them
kubectl get pods -n kafka
NAME READY STATUS RESTARTS AGE
my-cluster-entity-operator-746bcbb686-8hz2f 2/2 Running 1 (25h ago) 25h
my-cluster-kafka-0 1/1 Running 0 25h
my-cluster-kafka-1 1/1 Running 0 25h
my-cluster-kafka-2 1/1 Running 0 26h
my-cluster-zookeeper-0 1/1 Running 0 25h
my-cluster-zookeeper-1 1/1 Running 0 25h
my-cluster-zookeeper-2 1/1 Running 0 25h
kafka-ui-deployment-54585c7476-rjg86 1/1 Running 0 25h
strimzi-cluster-operator-56587547d6-5phmm 1/1 Running 0 25hstep-4 Created ingress to access kafka-ui on a specific domain
ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: kafka-ingress
annotations:
kubernetes.io/ingress.class: nginx
labels:
app: kafka-ingress
environment: prod-lke
spec:
rules:
- host: kafkaui.xyz.com ---> you domain
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: kafka-ui-service
port:
number: 8080
kubectl apply -f ingress.yaml -n kafkaAccessing kafkaui.xyz.com Can access you domain by using username and password (Kindly change the username and password in kafka-ui.yaml) username- admin password- pass
Note:- By using the above kafka-ui configuration, this kafka-ui user admin is having all the admin access of your kafka cluster.
You can check more info about: Kafka Cluster on Kubernetes with Strimzi .
Learn More With Trending Blogs: