Хакер - Фундаментальные основы хакерства. Как идентифицировать структуры и объекты в чужой программе
hacker_frei
Крис Касперски, Юрий Язев
Содержание статьи
- Идентификация структур
- Идентификация объектов
- Классы и объекты
- Мой адрес — не дом и не улица!
- Заключение
Когда разработчик пишет программу, он имеет возможность использовать такие достижения цивилизации, как структуры и классы. А вот реверсеру это лишь осложняет жизнь: ему ведь необходимо понимать, как компилятор обрабатывает высокоуровневые сущности и как с ними потом работает процессор. О способах нахождения в бинарном коде объектов и структур мы и поговорим.
После небольшой передышки продолжим сопоставлять дизассемблерные листинги для архитектуры x86-64 и конструкции языков высокого уровня (в наших примерах мы используем C/C++). Этим мы занимаемся (если ты по какой‑то нелепой причине не читал прошлые номера нашего журнала), чтобы точнее понять принцип работы программ, подвергнутых дизассемблированию, и освоить некоторые интересные приемы реверс‑инжиниринга.
C/C++ не единственный язык, на котором можно написать логику программы. Благодаря виртуальным машинам существуют более быстрые способы разработки хороших приложений, но модули безопасности программ по‑прежнему чаще всего создаются с помощью C/C++. А главная задача хакера — разгрызть модуль безопасности, чтобы нужная программа не требовала регистрационных ключей, ввода паролей или, того хуже, подключения к веб‑серверу разработчика.
Фундаментальные основы хакерства
Пятнадцать лет назад эпический труд Криса Касперски «Фундаментальные основы хакерства» был настольной книгой каждого начинающего исследователя в области компьютерной безопасности. Однако время идет, и знания, опубликованные Крисом, теряют актуальность. Редакторы «Хакера» попытались обновить этот объемный труд и перенести его из времен Windows 2000 и Visual Studio 6.0 во времена Windows 10 и Visual Studio 2019.
Ссылки на другие статьи из этого цикла ищи на странице автора.
Обращаю твое внимание на одну деталь: с текущей статьи я перехожу на Visual Studio 2019. Последняя версия датируется 17 сентября и имеет номер 16.7.5. Чтобы избежать возможных несостыковок, советую тебе тоже обновить «Студию».
ИДЕНТИФИКАЦИЯ СТРУКТУР
Структуры очень популярны среди программистов. Позволяя объединить под одной крышей родственные данные, они делают листинг программы более наглядным и упрощают его понимание. Соответственно, идентификация структур при дизассемблировании облегчает анализ кода. К великому сожалению исследователей, структуры как таковые существуют только в исходном тексте программы и практически полностью «перемалываются» при ее компиляции, становясь неотличимыми от обычных, никак не связанных друг с другом переменных.
Рассмотрим пример, демонстрирующий уничтожение структур на стадии компиляции:
#include <stdio.h>
#include <string.h>
struct zzz
{
char s0[16];
int a;
float f;
};
void func(struct zzz y)
// Понятное дело, передачи структуры по значению лучше избегать,
// но здесь это сделано умышленно для демонстрации скрытого создания
// локальной переменной
{
printf("%s %x %fn", &y.s0[0], y.a, y.f);
}
int main()
{
struct zzz y;
strcpy_s(&y.s0[0], 14, "Hello,Sailor!"); // Для копирования строки
y.a = 0x666; // используется безопасная версия функции
y.f = (float)6.6; // Чтобы подавить возражение компилятора,
func(y); // указываем целевой тип
}
Результат компиляции этого кода с помощью Visual Studio 2019 для платформы x64 должен выглядеть так:
main proc near
; Члены структуры неотличимы от обычных локальных переменных
var_48 = xmmword ptr -48h
var_38 = qword ptr -38h
Dst = byte ptr -28h
var_18 = qword ptr -18h
var_10 = qword ptr -10h
sub rsp, 68h
mov rax, cs:__security_cookie
xor rax, rsp
mov [rsp+68h+var_10], rax
; Подготовка параметров для вызова функции
lea r8, Src ; "Hello,Sailor!"
mov edx, 0Eh ; SizeInBytes
lea rcx, [rsp+68h+Dst] ; Dst
; Вызов функции для копирования строки из сегмента данных в локальную
; переменную
call cs:__imp_strcpy_s
Следующая команда копирует одно вещественное число, находящееся в младших 32 битах источника, — константу __real@40d33333 (смотрим, чему она равна при объявлении в секции rdata: __real@40d33333 dd 6.5999999, в формате float она будет равна 6.6) в младшие 32 бита приемника — 128-битного регистра XMM1. Напомню, восемь регистров XMM0 — XMM7 были добавлены в расширение SSE и поэтому впервые появились в процессоре Pentium III.
movss xmm1, cs:__real@40d33333
; Помещаем указатель на строку в регистр RDX
lea rdx, [rsp+68h+var_48]
Далее с использованием инструкции MOVUPS из расширения SSE копируются невыровненные куски по 16 бит. Таким образом, за раз копируются сразу восемь символов Unicode. Однако количество символов в строке вполне может быть не кратно восьми, поэтому используется именно эта инструкция — все остальные инструкции из расширения SSE оперируют с переменными, выровненными по 16-битным границам памяти. В ином случае они вызывают исключение.
movups xmm0, xmmword ptr [rsp+68h+Dst]
; В регистр RCX помещаем форматную строку для функции printf
lea rcx, _Format ; "%s %x %f\n"
; Помещаем двойное слово (значение 0x666) в переменную типа DWORD
mov dword ptr [rsp+68h+var_18], 666h ; --1
Следующая команда копирует строго двойное слово из памяти в регистр (у нас это XMM3). Значение, сохраненное в копируемой области памяти: 6.599999904632568, выровнено по границе 16 бит и на самом деле равно 6.6. В случае копирования из памяти в регистр (подобно нашему примеру) обнуляется старшее двойное слово источника.
movsd xmm3, cs:__real@401a666660000000
; Помещаем значение 0x666 в 32-битный регистр
mov r8d, 666h
; Из переменной (см. метку --1) копируем двойное слово в регистр
movsd xmm2, [rsp+68h+var_18]
Далее учетверенное слово (64 бит) копируется из регистра XMM3 расширения SSE в регистр общего назначения R9, добавленный вместе с расширением x86-64. Ведь AMD64, по сути, представляет собой такое же расширение процессорной архитектуры x86, как и SSE.
movq r9, xmm3
Инструкция shufps посредством битовой маски комбинирует и переставляет данные в 32-битных компонентах XMM-регистра. Таким образом, если представить 0E1h в бинарном виде, получим 11100001b. В соответствии с этой маской происходит трансформация всех четырех 32-битных частей регистра XMM2.
shufps xmm2, xmm2, 0E1h
; Копирование нижней 32-битной части источника в приемник
movss xmm2, xmm1
; Копирует 128 бит из регистра в переменную
movaps [rsp+68h+var_48], xmm0
; В соответствии с маской перемешивает содержимое регистра (см. выше)
shufps xmm2, xmm2, 0E1h
; Две следующие инструкции помещают значение регистра в переменные,
; находящиеся в памяти
movsd [rsp+68h+var_18], xmm2
movsd [rsp+68h+var_38], xmm2
; Все параметры находятся на своих местах, вызываем функцию printf
call printf
xor eax, eax
mov rcx, [rsp+68h+var_10]
xor rcx, rsp ; StackCookie
call __security_check_cookie
add rsp, 68h
retn
main endp
Компилятор сгенерировал довольно витиеватый код со множеством команд из расширения SSE. При этом он встроил функцию func прямо в main!
А теперь заменим структуру последовательным объявлением тех же самых переменных и рассмотрим пример, демонстрирующий сходство структур с обычными локальными переменными.
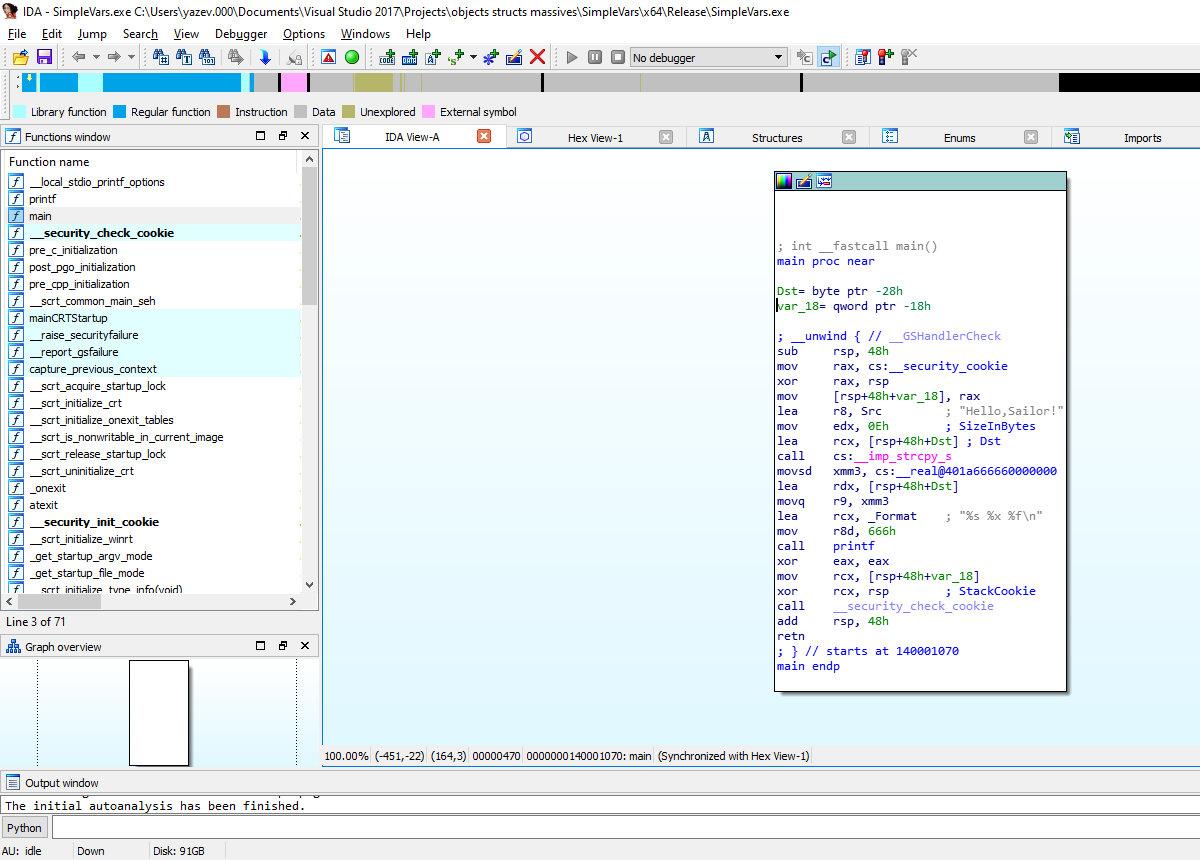
int main()
{
char s0[16];
int a;
float f;
strcpy_s(&s0[0], 14, "Hello,Sailor!");
a = 0x666;
f = (float)6.6;
printf("%s %x %fn", &s0[0], a, f);
}
И сравним результат компиляции с предыдущим:
main proc near
Dst = byte ptr -28h
var_18 = qword ptr -18h
; Есть различие! Компилятор избавился от ненужных для выполнения переменных,
; однако от этого не становится понятнее, принадлежат переменные структуре или нет
sub rsp, 48h
mov rax, cs:__security_cookie
xor rax, rsp
mov [rsp+48h+var_18], rax
; Готовим параметры
lea r8, Src ; "Hello,Sailor!"
mov edx, 0Eh ; SizeInBytes
lea rcx, [rsp+48h+Dst] ; Dst
; Вызываем функцию копирования строки
call cs:__imp_strcpy_s
; В XMM3 помещается значение 6.599999904632568 (подробно мы говорили,
; когда разбирали предыдущий листинг)
movsd xmm3, cs:__real@401a666660000000
; Последующие инструкции продолжают готовить параметры для функции
lea rdx, [rsp+48h+Dst]
movq r9, xmm3
; В регистр RCX помещаем форматную строку для функции printf
lea rcx, _Format ; "%s %x %f\n"
; Помещаем значение 0x666 в младшие 32 бита регистра R8
mov r8d, 666h
; Вызов функции printf
call printf
xor eax, eax
mov rcx, [rsp+48h+var_18]
xor rcx, rsp ; StackCookie
call __security_check_cookie
add rsp, 48h
retn
main endp
Без вызова дополнительных функций и передачи параметров дизассемблерный листинг заметно сократился. Остальной код остался идентичным предыдущему листингу.
Выходит, отличить структуру от обычных переменных невозможно? Неужто исследователю придется самостоятельно распознавать «родство» данных и связывать их «брачными узами», порой ошибаясь и неточно воспроизводя исходный текст программы?
Как сказать... И да и нет одновременно. «Да» — экземпляр структуры, использующийся в той же единице трансляции, в которой он был объявлен, «развертывается» еще на стадии компиляции в самостоятельные переменные. Обращение к ним происходит индивидуально по их фактическим адресам (возможно, косвенным). «Нет» — если в области видимости находится один лишь указатель на экземпляр структуры. Тогда обращение ко всем членам структуры выполняется через указатель на этот экземпляр, так как структура не присутствует в области видимости. Например, передается другой функции по ссылке, вычислить фактические адреса ее членов на стадии компиляции невозможно.
Постой, но ведь точно так устроено обращение и к элементам массива: базовый указатель указывает на начало массива, к нему добавляется смещение искомого элемента относительно начала массива (индекс элемента, умноженный на его размер), результат вычислений и будет фактическим указателем на искомый элемент!
Единственное фундаментальное отличие массивов от структур состоит в том, что массивы гомогенны (то есть состоят из элементов одного типа), а структуры могут быть как гомогенными, так и гетерогенными (состоящими из элементов различных типов). Таким образом, задача идентификации структур и массивов сводится, во‑первых, к выделению ячеек памяти, адресуемых через общий для них всех базовый указатель, и, во‑вторых, к определению типа этих переменных. Если удается выделить более одного типа, скорее всего, перед нами структура, в противном случае это с равным успехом может быть и структурой, и массивом — тут уж приходится смотреть по обстоятельствам.
С другой стороны, если программисту вздумается подсчитать зависимость выпитого количества пива от дня недели, он может либо выделить для учета массив day[7], либо завести структуру: struct week { int Monday; int Tuesday;...}. И в том и в другом случае сгенерированный компилятором код будет одинаков, да не только код, но и смысл! В этом контексте структура неотличима от массива и физически, и логически, выбор той или иной конструкции — дело вкуса.
Также возьми себе на заметку, что массивы, как правило, длинны, а обращение к их элементам часто сопровождается математическими операциями над указателем. Далее. Обработка элементов массива, как правило, выполняется в цикле, а члены структуры по обыкновению «разбираются» индивидуально (хотя некоторые программисты позволяют себе вольность обращаться со структурой как с массивом).
Еще неприятнее, что языки C/C++ допускают (если не сказать провоцируют) явное преобразование типов и... Oй, а ведь в этом случае при дизассемблировании не удастся установить, имеем ли мы дело с объединенными под одну крышу разнотипными данными (то есть структурой), или же это массив c ручным преобразованием типа своих элементов. Хотя, строго говоря, после подобных преобразований массив превращается в самую настоящую структуру! Массив по определению гомогенен и данные разных типов хранить не может.
Модифицируем предыдущий пример, передав функции не саму структуру, а указатель на нее:
...
// Подключение библиотек
...
// Объявление структуры
void func(zzz *y)
{
printf("%s %x %fn", y->s0, y->a, y->f);
}
int main()
{
zzz y;
strcpy_s(&y.s0[0], 14, "Hello,Sailor!"); // Для копирования строки
y.a = 0x666; // используется безопасная версия функции
y.f = (float)6.6;
func(&y);
}
Как видишь, изменения минимальны в сравнении с позапрошлым примером. Теперь посмотрим, что за код сгенерировал компилятор. После беглого взгляда на листинг ниже угадывается его сходство с дизассемблерным листингом программы из первого примера. Однако этот получился короче.
main proc near
Dst = byte ptr -28h
var_18 = dword ptr -18h
var_14 = dword ptr -14h
var_10 = qword ptr -10h
; Компилятор без зазрения совести опять запихнул функцию func внутрь main
sub rsp, 48h
mov rax, cs:__security_cookie
xor rax, rsp
mov [rsp+48h+var_10], rax
; Подготовка параметров для вызова функции
lea r8, Src ; "Hello,Sailor!"
mov edx, 0Eh ; SizeInBytes
lea rcx, [rsp+48h+Dst] ; Dst
; Вызов функции для копирования строки
call cs:__imp_strcpy_s
Команда MOVSD копирует двойное слово из памяти в регистр (в нашем случае — XMM3).
movsd xmm3, cs:__real@401a666660000000
; Помещаем указатель на строку в регистр RDX
lea rdx, [rsp+48h+Dst]
Копируем 32-битное значение с плавающей запятой одинарной точности из памяти в регистр XMM0, при этом обнуляя его верхние 96 бит. Очевидно, происходит подготовка параметров для вызова функции printf, они размещаются в регистрах процессора.
movss xmm0, cs:__real@40d33333
; В регистр RCX помещаем форматную строку для функции printf
lea rcx, _Format ; "%s %x %f\n"
Как мы помним (а если нет, надо поднять глазки вверх), в нижних 64 битах регистра XMM3 находится число 6.6, поэтому с помощью инструкции MOVQ копируем эти 64 бита в регистр R9.
movq r9, xmm3
Следующая инструкция копирует нижние 32 бита 128-битного регистра XMM0 в область памяти — переменную var_14. Как мы помним, в данном регистре находится число 6.6.
movss [rsp+48h+var_14], xmm0
; Помещаем в регистр R8D значение 0x666
mov r8d, 666h
; Помещаем то же число в область памяти, другими словами —
; инициализируем переменную var_18
mov [rsp+48h+var_18], 666h
; Все параметры на своих местах,
; вызываем функцию для вывода строки на консоль
call printf
xor eax, eax
mov rcx, [rsp+48h+var_10]
xor rcx, rsp ; StackCookie
call __security_check_cookie
add rsp, 48h
retn
main endp
Компилятор все конкретно заоптимизировал. И кажется, восстановить изначальную структуру нет никакой возможности. В то же время при сравнении этого листинга с предыдущим наблюдаются заметные различия. Этот стал короче и лаконичнее, но это нисколько не помогает опознать структуру. Надо хотя бы попробовать определить начальные типы переменных. Поэтому попытаемся поглубже размотать код и обратим внимание на начало функции main:
Dst = byte ptr -28h
var_18 = dword ptr -18h
var_14 = dword ptr -14h
var_10 = qword ptr -10h
Очевидно, здесь объявляются четыре переменные. Их производный (в скомпилированном виде) тип данных указан после знака равенства, далее идет смещение, задаваемое в байтах. Производный тип определяет вместимость (другими словами, размер) переменной.
У переменных, объявленных внутри функции, смещение отрицательное, тогда как у аргументов, получаемых функцией, смещение положительное. Смещение вычисляется относительно вершины стека запускаемой функции. Его значение хранится в регистре RSP. Если заглянуть в стек функции main, мы обнаружим, что значения переменных не определены. Ясное дело, локальные переменные существуют только в момент выполнения функции, в которой они объявлены:
Dst db ?
...
var_18 dd ?
var_14 dd ?
var_10 dq ?
Тем не менее они определяются в начале использующей их функции (предыдущий листинг). Посмотрим на использование переменных: mov [rsp+48h+var_10], rax. Из чего следует: содержимое регистра RAX записать в область памяти по адресу RSP + 72 – 16 == RSP + 56 (в десятичной системе). Или для примера рассмотрим другую инструкцию: lea rcx, [rsp+48h+Dst]. То есть в регистр RCX записать эффективный адрес, иными словами — указатель на область памяти RSP + 72 – 40 == RSP + 32 (в десятичной системе).
Как известно, стек растет сверху вниз, то есть объявленные позднее переменные имеют меньший адрес. Поэтому и говорится, что RSP указывает на вершину стека. Но так определено для x86 и, соответственно, x86-64. Для других процессорных архитектур дела могут обстоять по‑другому. Чтобы проверить, куда растет стек, можно запустить такую простенькую программу:
#include <stdio.h>
int main()
{
int a, b;
if (&a < &b)
printf("%s", "Stack grows upn");
else
printf("%s", "Stack grows downn");
printf("First variable adress: %pnSecond variable adress: %pn", &a, &b);
return 0;
}
Ее выполнение приведет примерно к такому результату (в твоем случае адреса могут иметь другие значения).

При перезапуске программы адреса будут меняться, однако их различие составит 4 байта — размер типа данных int, при этом объявленная второй переменная будет меньше (вспомни о росте стека).
Теперь снова взглянем на объявление переменных в дизассемблерном листинге:
Dst = byte ptr -28h
var_18 = dword ptr -18h
var_14 = dword ptr -14h
var_10 = qword ptr -10h
Отсюда следует: var_10 = 4 байта — целочисленный тип или тип с плавающей запятой (так как и int, и float занимают в памяти 4 байта), var_14 — тоже 4 байта со всеми вытекающими отсюда последствиями, var_18 — 16 байт. Получается, что это массив на 16 элементов типа char, так как элемент последнего занимает 1 байт. Конечно, если бы нам были неизвестны начальные типы данных, нам бы пришлось решать эту головоломку куда дольше!
Погляди‑ка, обращения к значениям в памяти (или для записи в память) происходят через адрес [rsp+48h+…], дальше идет смещение определенной переменной. Таким образом, можно сделать вывод: три определенные переменные входят в один контейнер. Но так как переменные имеют разные типы данных, этим контейнером никаким боком не может быть массив, следовательно, это структура!
Фактически функция main выполняет три операции: загружает значения, преобразует их и вызывает printf, предварительно разместив значения в регистрах процессора для передачи их в качестве параметров. Как мы помним, в x86-64 согласно ДИП (двоичный интерфейс приложений) от Microsoft первые четыре параметра размещаются в регистрах. Рассмотрим начало получающей эти параметры функцию printf:
printf proc near
var_28 = qword ptr -28h
arg_0 = qword ptr 8
arg_8 = qword ptr 10h
arg_10 = qword ptr 18h
arg_18 = qword ptr 20h
mov [rsp+arg_0], rcx
mov [rsp+arg_8], rdx
mov [rsp+arg_10], r8
mov [rsp+arg_18], r9
В начале функции инициализируются локальные переменные: значения извлекаются из регистров процессора и помещаются в память.
ИДЕНТИФИКАЦИЯ ОБЪЕКТОВ
Объекты языка C++ — это, по сути дела, структуры, совмещающие в себе данные, методы их обработки (то бишь функции) и атрибуты защиты (типа public, friend).
Элементы — данные объекта обрабатываются компилятором, равно как и обычные члены структуры. Невиртуальные функции вызываются по фактическому смещению и в объекте отсутствуют. Виртуальные функции вызываются через специальный указатель на виртуальную таблицу, помещенный в объект, а атрибуты защиты уничтожаются еще на стадии компиляции. Отличить публичную функцию от защищенной можно благодаря тому, что публичная может быть вызвана из постороннего кода, а защищенная — только из методов своего объекта.
Теперь обо всем этом подробнее. Итак, что представляет собой объект (или экземпляр класса)?
Рассмотрим следующий листинг, демонстрирующий строение объекта:
class MyClass
{
int a;
int b;
void demo_1(void);
public:
int c;
virtual void demo_2(void);
};
MyClass zzz;
Экземпляр класса MyClass «перемелется» компилятором в следующую структуру.
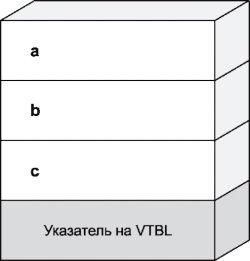
Перед исследователем встают следующие проблемы: как отличить объекты от простых структур? Как определить размер объектов? Как определить, какая функция какому объекту принадлежит? Как... Погоди, погоди, не все сразу! Начнем отвечать на вопросы по порядку.
Вообще, строго говоря, отличить объект от структуры невозможно из‑за того, что объект и есть структура с членами, приватными по умолчанию. При объявлении объектов можно пользоваться и ключевым словом struct, и ключевым словом class. Причем для классов, все члены которых открыты, предпочтительнее использовать именно struct, так как члены структуры уже публичны по умолчанию. Сравни два следующих примера.
Пример 1
struct MyClass
{
int x;
void demo(void);
private:
int y;
void demo_private(void);
};
Пример 2
class MyClass
{
int y;
void demo_private(void);
public:
int x;
void demo(void);
};
Одна запись отличается от другой лишь синтаксически, а код, генерируемый компилятором, будет идентичен! Поэтому с надеждой научиться различать объекты и структуры следует как можно скорее расстаться.
Окей, условимся считать объектами структуры, содержащие одну или больше функций. Вот только как определить, какая функция какому объекту принадлежит? С виртуальными функциями все просто — они вызываются косвенно, через указатель на виртуальную таблицу, помещаемый компилятором в каждый экземпляр класса, которому принадлежит данная виртуальная функция. Невиртуальные функции вызываются по их фактическому адресу, равно как и обычные функции, не принадлежащие никакому объекту.
Положение безнадежно? Отнюдь нет! Каждой функции — члену объекта передается неявный аргумент — указатель this, ссылающийся на объект, которому принадлежит данная функция. Экземпляр класса — это по факту не сам класс, но нечто очень тесно с ним связанное, поэтому восстановить исходную структуру классов дизассемблируемой программы вполне реально.
Размер объектов определяется теми же указателями this — как разница соседних указателей (если объекты расположены в стеке или в сегменте данных). Если же экземпляры объектов создаются оператором new (как часто и бывает), то в код помещается вызов функции new, принимающий в качестве аргумента количество выделяемых байтов, это и есть размер объекта.
Вот, собственно, и все. Остается добавить, что многие компиляторы, создавая экземпляр класса, не содержащего ни данных, ни виртуальных функций, все равно выделяют под него минимальное количество памяти (обычно один байт), хотя никак его не используют. На какой же, извините за грубость, хвост такое делать? Память — она ведь не резиновая, а из кучи одни байты и не выделишь — за счет грануляции отъедается солидный кусок, размер которого варьируется в зависимости от реализации самой кучи от 4 байт до 4 килобайт!
Причина в том, что компилятору жизненно необходимо определить указатель this, — нулевым, увы, this быть не может, это вызвало бы исключение при первой же попытке обращения. Да и оператору delete надо что‑то удалять, а раз так, это «что‑то» надо предварительно выделить...
Эх, хоть разработчики C++ не устают повторять, что их язык не уступает по эффективности чистому C, все известные мне реализации компиляторов C++ генерируют ну очень кривой и тормозной код!
Ладно, все это лирика, перейдем к конкретным примерам.
#include <stdio.h>
class MyClass
{
public:
int x;
void demo(void);
private:
int y;
void demo_private(void);
};
void MyClass::demo_private(void)
{
printf("Privaten");
}
void MyClass::demo(void)
{
printf("MyClassn");
this->demo_private();
this->y = 0x666;
}
int main()
{
MyClass* zzz = new MyClass;
zzz->demo();
zzz->x = 0x777;
delete zzz;
}
Если сейчас взять и с ходу запустить компиляцию, то оптимизирующий компилятор снова в труху перемелет наш объект и даже не создаст отдельные методы. Поэтому, чтобы увидеть магию ООП, нам придется отключить оптимизацию. Программисты редко так поступают, тем более в наше время, когда скорость работы приложения важнее его размера. Но нам придется пойти на эту неуклюжую уловку во имя знаний. Поэтому, отпив пивка (кофе, какао — по вкусу), отключи оптимизацию в свойствах проекта в Visual Studio.
В итоге дизассемблированный листинг в IDA PRO будет выглядеть примерно так:
main proc near
var_28 = qword ptr -28h
block = qword ptr -20h
var_18 = qword ptr -18h
var_10 = qword ptr -10h
sub rsp, 48h
mov ecx, 8 ; size
Выделяем 8 байт под экземпляр объекта оператором new. Вообще‑то вовсе не факт, что память выделяется именно под объект (может, тут было что‑то типа char *x = new char[8]), так что не будем считать это утверждение догмой, а примем как рабочую гипотезу. Дальнейшие исследования покажут, что к чему.
call operator new(unsigned __int64)
mov [rsp+48h+var_18], rax
mov rax, [rsp+48h+var_18]
mov [rsp+48h+var_28], rax
Ухо‑хвост! Готовится указатель this, который передается функции через регистр. Значит, внутри RCX не что иное, как указатель на экземпляр класса!
mov rcx, [rsp+48h+var_28] ; this
Вот мы и добрались до вызова функции demo — открываем хвост! Пока неясно, что эта функция делает (символьное имя дано ей для наглядности), тем не менее известно, что она принадлежит экземпляру класса, на который указывает RCX. Назовем этот экземпляр A. Далее, поскольку функция, вызывающая demo (то есть функция, в которой мы сейчас находимся), не принадлежит к А (она же его сама и создала — не мог экземпляр класса сам «вытянуть себя за хвост»), значит, функция demo — это public-функция. Неплохо для начала?
call MyClass::demo(void)
mov rax, [rsp+48h+var_28]
mov dword ptr [rax], 777h
Так‑так... Мы помним, что RAX указывает на экземпляр класса. Тогда выходит, что в объекте есть еще один public-член, и это переменная типа int. Далее в остатке функции содержится код, служащий для удаления объекта из кучи, плюс эпилог.
mov rax, [rsp+48h+var_28]
mov [rsp+48h+block], rax
mov edx, 8 ; __formal
mov rcx, [rsp+48h+block] ; block
call operator delete(void *,unsigned __int64)
cmp [rsp+48h+block], 0
jnz short loc_14000118E
mov [rsp+48h+var_10], 0
jmp short loc_1400011A1
; ----------------------------------
loc_14000118E: ; CODE XREF: main+51↑j
mov [rsp+48h+var_28], 8123h
mov rax, [rsp+48h+var_28]
mov [rsp+48h+var_10], rax
loc_1400011A1: ; CODE XREF: main+5C↑j
xor eax, eax
add rsp, 48h
retn
main endp
По предварительным заключениям класс выглядит следующим образом:
class myclass
{
public:
void demo(void); // void — так как функция ничего не принимает и не возвращает
int x;
}
Вот перед нами функция demo — метод объекта A:
public: void MyClass::demo(void) proc near
arg_0 = qword ptr 8
; Загружаем в область памяти указатель this, переданный функции через регистр
mov [rsp+arg_0], rcx
sub rsp, 28h
lea rcx, aMyclass ; "MyClass\n"
; Выводим строку на экран
call printf
mov rcx, [rsp+28h+arg_0] ; this
Оп, вот он, наш обладатель хвоста! Вызывается еще одна функция! Судя по this, это метод нашего объекта, причем, вероятнее всего, имеющий атрибут private, поскольку вызывается только из функции самого объекта.
call MyClass::demo_private(void)
mov rax, [rsp+28h+arg_0]
mov dword ptr [rax+4], 666h
; Так, в объекте есть еще одна переменная, вероятно приватная
add rsp, 28h
retn
public: void MyClass::demo(void) endp
Тогда, по современным воззрениям, класс должен выглядеть так:
class myclass
{
void demo_private(void);
int y;
public:
void demo(void);
int x;
}
Итак, мы не только идентифицировали объект, но и восстановили его структуру! Пускай не застрахованную от ошибок (так, предположение о приватности demo_private и у базируется лишь на том, что они ни разу не вызывались извне объекта), но все же не так ООП страшно, как его малюют, и восстановить если не подлинный исходный текст программы, то хотя бы какое‑то его подобие вполне возможно!
private: void MyClass::demo_private(void) proc near
; Закрытый метод demo_private — ничего интересного
arg_0 = qword ptr 8
mov [rsp+arg_0], rcx
sub rsp, 28h
lea rcx, _Format ; "Private\n"
call printf
add rsp, 28h
retn
private: void MyClass::demo_private(void) endp
Обрати также внимание, мы не создаем кастомные конструктор и деструктор, отдавая задачу создания конструктора и деструктора компилятору. Автоматическое создание этих методов при их отсутствии прописано в стандарте языка C++.
КЛАССЫ И ОБЪЕКТЫ
В сгенерированном компилятором коде никаких классов и в помине нет, одни лишь экземпляры классов. Вроде бы, да какая разница‑то? Экземпляр класса разве не есть сам класс? Нет, между классом и объектом существует принципиальная разница. Класс — это структура, в то время как экземпляр класса (в сгенерированном коде) — подструктура этой структуры.
Иными словами, пусть имеется класс А, включающий в себя функции a1 и а2. Пусть создано два его экземпляра — из одного мы вызываем функцию a1, из другого — a2. С помощью указателя this мы сможем выяснить лишь то, что одному экземпляру принадлежит функция a1, другому — a2. Но установить, экземпляры это одного класса или двух разных классов, невозможно!
Дело осложняется тем, что в производных классах наследуемые функции не дублируются (во всяком случае, так поступают «умные» компиляторы, хотя в жизни случается всякое). Возникает двузначность: если с одним экземпляром связаны функции a1 и a2, а с другим — a1, a2 и a3, то это могут быть либо экземпляры одного класса (просто из первого экземпляра функция a3 не вызывается), либо второй экземпляр — экземпляр класса, производного от первого. Код, сгенерированный компилятором, в обоих случаях будет идентичным! Приходится восстанавливать иерархию классов по смыслу и назначению принадлежащих им функций... Понятное дело, приблизиться к исходному коду сможет только ясновидящий.
Словом, как бы там ни было, никогда не путай экземпляр класса с самим классом и не забывай, что объекты существуют только в исходном тексте и уничтожаются на стадии компиляции.
Мой адрес — не дом и не улица!
Где живут структуры, массивы и объекты? Конечно же, в памяти! А поконкретнее? Конкретнее — существуют три типа размещения: в стеке (автоматическая память), сегменте данных (статическая память) и куче (динамическая память). И каждый тип со своим характером.
Возьмем стек — выделение памяти неявное, фактически происходит на этапе компиляции, причем гарантированно определяется только общий объем памяти, выделенный под все локальные переменные. А определить, сколько занимает каждая из них, невозможно в принципе. Не веришь? А вот, скажем, пусть будет такой код: char a1[13]; char a2[17]; char a3[23]. Если компилятор выровняет массивы по кратным адресам (а это делают многие компиляторы), то разница смещений ближайших друг к другу массивов может и не быть равна их размеру. Единственная надежда восстановить подлинный размер — найти в коде проверки выходы за границы массива (если они есть, а их часто не бывает).
Второе (самое неприятное): если один из массивов не используется, а только объявляется, то неоптимизирующие компиляторы (и даже некоторые оптимизирующие!) могут тем не менее отвести для него стековое пространство. Тем самым он вплотную примкнет к предыдущему массиву, и гадай: то ли размер массива такой, то ли в его конец «вбухан» неиспользуемый массив! Ну, с массивами куда бы еще ни шло, а вот со структурами и объектами дела обстоят намного хуже. Никому и в голову не придет помещать в программу код, отслеживающий выход за пределы структуры (объекта). Такое невозможно в принципе (ну разве что программист слишком вольно работает с указателями)!
Ладно, оставим в стороне размер, перейдем к проблемам «разверстки» и поиску указателей. Как уже говорилось выше, если массив (объект, структура) объявляется в непосредственной области видимости единицы трансляции, он «вспарывается» на этапе компиляции и обращение к его членам выполняется по фактическому смещению, а не по базовому указателю. К счастью, идентификацию объектов облегчает наличие в них указателя на виртуальную таблицу, но ведь не факт, что любая таблица указателей на функции есть виртуальная таблица! Может, это просто массив указателей на функции, определенный самим программистом? Вообще‑то при наличии опыта такие случаи можно легко распознать, но все‑таки они достаточно неприятны.
С объектами, расположенными в статической памяти, дела обстоят намного проще. Из‑за своей глобальности они имеют специальный флаг, предотвращающий повторный вызов конструктора, поэтому отличить объект, расположенный в сегменте данных, от структуры или массива становится очень легко. С определением его размера, правда, все те же неувязки.
Наконец, объекты (структуры, массивы), расположенные в куче, просто сказка для анализа! Память отводит функция, которая явно принимает количество выделяемых байтов в качестве своего аргумента и возвращает указатель, гарантированно указывающий на начало экземпляра объекта (структуры, массива). Радует и то, что обращение к элементам всегда идет через базовый указатель, даже если объявление совершается в области видимости (иначе и быть не может: фактические адреса выделяемых блоков динамической памяти неизвестны на стадии компиляции).
ЗАКЛЮЧЕНИЕ
Архитектура x86-64, по сути, такое же расширение для процессора архитектуры x86, как SSE. Все многообразие подобных расширений для x86, как 3DNOW, MMX, SSE, VMX, AVX и другие, добавляют процессору дополнительные регистры, способные хранить большие значения. Вместе с тем процессоры получают новые инструкции для обработки содержащихся в этих регистрах данных: они могут извлекать отдельные слова, двойные слова, 64-разрядные слова и более за один такт. Как мы увидели, современный компилятор от Microsoft даже для примитивного консольного приложения, которое мы использовали для демонстрации, генерирует код с примесью SSE.
Целью сегодняшней статьи было научиться идентифицировать комплексные языковые конструкции языков высокого уровня — структуры и объекты. Мы разобрались, как их выделить из общего ряда переменных и функций, как установить взаимосвязь между элементами одного объекта и как восстановить начальную структуру класса и структуры. Для этого надо полагаться больше на способности серого вещества в черепной коробке, нежели на программные инструменты. Поэтому очень часто приходится включать логику. Как говорится, главный инструмент для взлома находится у тебя в голове. И наконец, с помощью лаконичных экземпляров кода мы побайтно рассмотрели широкий спектр применения разных подходов определения классов и структур.
Оптимизирующий компилятор генерирует максимально элементарный код, стирая любые зацепки, за которые можно было бы ухватиться для распознавания структур языков высокого уровня. Но хакеры тоже не лыком шиты и могут найти уйму лазеек для расшифровки бинарников.
В конце семидесятых годов прошлого века производители полупроводников как раз работали над процессорами, способными переварить всю кухню ООП, но выпущенный впопыхах для удовлетворения рынка как промежуточное звено процессор 8086 показал, что упрощение кода куда важнее его усложнения. Тем самым на процессорах, способных на аппаратном уровне понимать ООП, поставили крест.
В следующей статье мы снова погрузимся в разделы памяти операционной системы и разберемся в принципах организации кучи.
Читайте ещё больше платных статей бесплатно: https://t.me/hacker_frei