Хакер - Самый быстрый укол. Оптимизируем Blind SQL-инъекцию
hacker_frei
Павел Сорокин
Содержание статьи
- Что такое «слепые» SQL-инъекции
- Факторы, влияющие на скорость эксплуатации
- Общие идеи повышения производительности
- Работа с сессиями
- Многопоточность
- Основные задачи эксплуатации
- Определение количества записей и длины строк
- Поиск целых чисел
- Работа с диапазонами поиска
- Сужение диапазона поиска
- Определение ошибок
- Поиск в диапазонах с разрывами
- Подстройка диапазона поиска
- Другие идеи оптимизации
- Соединение строк
- Работа с UNICODE
- Сжатие данных
- А что там sqlmap?
- Работа с потоками
- Определение длины строки
- Поиск символов
- Выбор диапазона символов
- Unicode
- Выводы
В своей практике работы в BI.ZONE я регулярно сталкиваюсь с необходимостью эксплуатации слепых SQL-инъекций. Пожалуй, Blind-случаи встречались мне даже чаще, чем Union или Error-based. Поэтому я решил подумать об эффективности. Эта статья — обзор подходов к эксплуатации слепых SQL-инъекций и техник, позволяющих ускорить эксплуатацию.
ЧТО ТАКОЕ «СЛЕПЫЕ» SQL-ИНЪЕКЦИИ
Здесь мы разберем случаи, при которых возникают Blind SQL-инъекции, а также описана базовая техника их эксплуатации. Если ты уже c ними знаком и понимаешь, что такое бинарный поиск, — смело переходи к следующему разделу.
Blind SQL-инъекции возникают, когда мы не можем напрямую достать данные из приложения, но можем различить два разных состояния веб‑приложения в зависимости от условия, которое мы определяем в SQL-запросе.
Как работает Blind SQL-инъекция
Представим следующую инъекцию (для простоты используем язык PHP, а в качестве СУБД возьмем MySQL):
$query = "SELECT id,name FROM products ORDER BY ".$_GET['order'];
Здесь мы можем указать в параметре order не только имя колонки, но и некоторое условие, например:
order=(if( (select 1=1),id,name))
order=(if( (select 1=0),id,name))
В зависимости от истинности логического выражения (1=1) или (1=0) результат будет отсортирован СУБД либо по колонке id, либо по колонке name. В ответе веб‑приложения мы увидим, по какой колонке отсортированы products, и сможем отличить истинное условие от ложного. Это позволяет нам «задавать вопросы» СУБД, на которые мы будем получать ответы «да» или «нет».
Например, «спросим» у СУБД — в таблице information_schema.tables больше 50 строк или нет?
order=(if( (select count(*)>50 from information_schema.tables),id,name))`
Если говорить более формально, то за один запрос мы можем получить 1 бит информации из базы данных. Для получения текстовой информации можно делать полный перебор всех возможных символов следующим образом:
order=(if( (select substring(password,1,1)='a' from users where username='admin'),id,name))
order=(if( (select substring(password,1,1)='b' from users where username='admin'),id,name))
order=(if( (select substring(password,1,1)='c' from users where username='admin'),id,name))
...
Но это долго — нужно сделать столько запросов, сколько букв мы хотим проверить. Именно поэтому, чтобы ускорить процесс, прибегают к бинарному поиску.
Как выполнить бинарный поиск
Переведем символ искомой строки в его ASCII-код и сделаем некоторое предположение о возможных значениях этого символа. Например, можно предположить, что он лежит в нижней половине ASCII-таблицы, то есть имеет код в диапазоне от 0x00 до 0x7f. Разделим этот диапазон пополам и спросим у БД — в какой половине диапазона находится символ?
order=(if( (select ascii(substring(password,1,1))>0x3f from users where username='admin'),id,name))
Если символ окажется больше 0x3f, значит, целевой диапазон сужается до 0x40-0x7f, если меньше — до 0x00-0x3f. Далее находим середину диапазона и снова спрашиваем у БД: целевой символ больше середины или меньше? Потом снова сужаем диапазон и продолжаем до тех пор, пока в диапазоне не останется ровно одно значение. Это значение и будет ответом.
В данном случае для поиска точного значения символа нам потребуется ровно log2(128)=7
запросов.
ФАКТОРЫ, ВЛИЯЮЩИЕ НА СКОРОСТЬ ЭКСПЛУАТАЦИИ
Теперь разберемся, что ограничивает скорость эксплуатации инъекции:
- При эксплуатации Blind SQL-инъекции атакующий отправляет запросы на один и тот же эндпоинт. Один такой запрос обрабатывается веб‑сервером некоторое время. Обозначим среднее время выполнения запроса — t0
- . Разброс времени выполнения запросов обычно невелик.
- Веб‑сервер может обрабатывать некоторое количество запросов параллельно. Оно зависит от количества физических веб‑серверов за балансировщиком, потоков веб‑приложения, ядер на сервере СУБД и т.д. Его можно выяснить эксперементально. Обозначим количество запросов к веб‑серверу — n0.
- Соответственно, приложение не будет обрабатывать больше чем
- F0=n0t0
- запросов в секунду. Мы можем отправить и больше запросов в секунду, но они будут попадать в очередь и ждать обработки, поэтому общая скорость обработвки запросов не превысит F0
- . Данный параметр может меняться в зависимости от текущей нагрузки на приложение и быть непостоянным, но не суть.
Вывод: cкорость, с которой мы можем вынимать данные, составляет ~=F0
бит в секунду. Это основное ограничение по скорости эксплуатации слепых SQL-инъекций.
ОБЩИЕ ИДЕИ ПОВЫШЕНИЯ ПРОИЗВОДИТЕЛЬНОСТИ
Работа с сессиями
Веб‑приложение может не выполнять паралельные запросы в рамках одной сессии (например, так работает PHP). Если мы видим, что подбор идет в один поток, то нужно создать по сессии для каждого потока подбора.
Также, если веб‑приложение выполняется на нескольких серверах и использует балансировку на основе Sticky Sessions, все запросы в рамках сессии отправляются на один и тот же сервер. Мы можем создать несколько сессий на разных серверах и распределить запросы равномерно по ним. В обработку запросов будет вовлечено большее количество серверов — следовательно, n0
повыситься, а вместе с ним и общая скорость атаки.
Многопоточность
Получить больше чем F0
битов в секунду мы не можем никак. Однако мы можем грамотно распорядиться имеющейся скоростью и тем самым увеличить общую скорость проведения атаки.
Как правило, наша задача — вытащить несколько колонок из одной таблицы (возможно, с применением фильтра WHERE). Реализация такой атаки «в лоб» состоит из следующих задач:
- Определить количество строк, которое надо вернуть.
- Для каждой строки и колонки, которые надо вернуть, определить длину строки.
- Выполнить поиск каждого символа целевой строки. Если мы считаем что нам нужны только стандартные символы из нижней половины ASCII-таблицы (
0x00-0x7f), то это 7 запросов на один символ.
Банальная реализация
При банальной реализации «в лоб» распараллеливание делается только на третьем этапе. На первом и втором этапе идет подбор в 1 поток, это означает, что скорость составляет
1t0
запросов в секунду вместо доступных
n0t0.
На третьем этапе распараллеливание делается таким образом. Допустим, веб‑приложение обрабатывает n0
одновременных запросов, а длина строки составляет X
. Таким образом мы можем выполнять n0
параллельных задач, каждую из которых удобно поместить в отдельный поток.
Сначала определяем первые n0
символов строки параллельно. Нужно помнить, что мы не можем использовать все доступные потоки для определения какого‑то одного символа, так как бинарный поиск требует получения ответа на предыдущий запрос для формирования нового запроса.
По мере завершения поиска символов мы запускаем новые потоки для следующих символов той же строки. Но так как скорость выполнения запросов примерно одинакова, новые n0
потоков мы запустим примерно тогда, когда первые n0
потоков завершаться, а именно через 7∗t0
секунд (если ищем в диапазоне 0x00-0x7f).
Если длина строки кратна n0
, то все хорошо и все потоки будут работать на максимальной скорости. Если же нет, то последняя группа после кратности n0
будет работать в X mod (n0)
потоков. Остальные потоки будут простаивать. Наконец, если длина строки случайная, то очевидно, что в среднем последняя группа будет работать только на 50% от максимальной скорости.
Более производительный вариант
Для увеличения скорости можно лучше использовать параллельность: запустить первый поток для решения задачи 1, а оставшиеся n0−1
свободных потоков сразу запустить на определение длин строк для первых
n0−1c
строк, где c
— количество колонок. Если окажется, что строк нужно запросить меньше, чем мы определили, то часть потоков отработала бессмысленно. Но иначе они бы просто простаивали, так что скорость атаки не упадет, но может увеличиться.
Можно пойти и еще дальше, сделав вероятное допущение о том, что целевые строки имеют длину не меньше, например, 3-х символов. Не завершив ни задачу 1, ни задачу 2, начать выполнять задачу 3, начать определять первые 3 символа первых целевых строк. После такого старта, если грамотно распорядиться потоками (например, иметь уже определенные длины для нескольких следующих строк заранее), можно поддерживать общую скорость ~=F0.
ОСНОВНЫЕ ЗАДАЧИ ЭКСПЛУАТАЦИИ
В данном разделе рассмотрим две типовые задачи, возникающие при эксплуатации слепых SQL-инъекций и способы их эффективного решения: определение количества записей и длины строк и поиск целых чисел.
Определение количества записей и длины строк
Определение количества возвращаемых записей (row) и длины строк — схожие задачи, но они не так тривиальны, как могут изначально показаться.
Бинарный поиск может искать значение в рамках какого‑то диапазона, у которого есть минимальное и максимальное значение. Так, при определении символов мы знаем, что они, скорее всего, лежат в диапазоне 0x00-0x7f и точно попадают в 0x00-0xff (Unicode пока опустим, хотя и для него тоже можно задать максимальную границу диапазона).
Для определения же количества записей и длины строк мы не обладаем такой информацией, поэтому теоретически целевое значение может быть абсолютно любым.
Также важно отметить, что определение количества записей — это операция, которая делается один раз для каждого запроса. А вот длина строки определяется многократно, поэтому оптимизация определения длины строки является более приоритетной задачей.
Определяем длину строки (банальный способ)
Сначала я приведу банальный алгоритм, который позволяет определить длину строки. Изучив его и поняв сопутствующие проблемы, мы сможем обсудить проблемы оценки эффективности таких алгоритмов.
Первой идеей, которая приходит в голову, является попытка определения значения, которое больше длины строки (далее рассуждения будут касаться только длины строки, для определения количества row они аналогичны). После обнаружения такого значения мы уже можем свободно запустить бинарный поиск.
Так как бинарный поиск имеет наибольшую эффективность при работе с диапазонами, размер которых равен точной степени двойки (это будет показано далее в статье), можно отталкиваться от какого‑то стартового числа — точной степени двойки, например 256.
Алгоритм получается следующий:
- Сравниваем длину строки с 256.
- Если длина меньше, то запускаем бинарный поиск, который будет требовать ln2(256)=8
- запросов.
- Если длина больше, то нам нужно увеличить максимальный диапазон. Например, можно умножить старую верхнюю границу на 24
- и сравнить с ней. Если окажется меньше, то запускаем бинарный поиск, если больше, то умножаем на 24
- еще раз и так далее.
Для расчета эффективности такого алгоритма нам нужно сделать предположение о вероятностном распределении длин искомых строк. Такое предположение сделать непросто, т.к. строки будут сильно зависеть от смысла, который они несут. Например, email-адреса имеют одно распределение, текстовые посты — другое, а хеши паролей вообще всегда имеют одинаковую длину.
Также стоит учитывать обычные практические задачи. Эксплуатация слепых SQL-инъекций — дело небыстрое. Скорее всего, если мы нашли строку, длина которой составляет 10 000 символов, нам не будет интересно вынимать ее целиком. Возможно, мы заходим посмотреть на первые 100 символов, чтобы понять, что вообще в ней содержится.
Таким образом, если длина строки больше, чем, например, 128 символов, то нас и не интересует ее точная длина — можно в выводе просто указать, что длина больше 128 символов, и при этом найти только эти самые первые 128 символов. В итоге получаем, что на определение длины строки мы тратим 7 запросов, как на 1 символ. На мой взгляд — вполне приемлемо.
Определяем длину строки (небанальный способ)
Также есть техника, в которой длину строки можно не определять в принципе.
При определении символов, как правило, используется конструкция
ASCII(substring(target_col,n,1))
Если n больше, чем длина строки, то функция substring вернет пустую строку, а функция ASCII от пустой строки вернет 0x00 (это верно для MySQL и PostgreSQL). Соответственно, как только мы обнаружили нулевой символ, мы считаем, что мы обнаружили последний символ и дальше искать не надо.
В данном подходе мы осуществляем поиск символа за последним, что дает лишних 7 запросов. Траты аналогичны тратам на определение длины строки. Также учтем, что в MSSQL и SQLite функция substring вернет не пустую строку, а NULL, как и функция ASCII/Unicode. Можно создавать особые конструкции, приводящие NULL в 0, однако это требует увеличения длины запроса. Кроме того, мы должны аккуратно выстраивать параллельность: подбор нескольких символов одновременно может привести к бесполезному поиску за концом строки и лишнему расходу запросов.
Если нам все же требуется определить длину строки точно (как и точное количество возвращаемых записей), возможные техники приведены далее.
Поиск целых чисел
Если искомая колонка является целочисленной, то у нас есть банальный вариант — привести число к строке и получить его как строку. Также мы можем воспользоваться бинарным поиском, но нам надо решить уже упомянутую проблему — определить верхнюю границу бинарного поиска:
- Будем считать, что размер числа ограничен 64 битами. При этом число не отрицательное — unsigned. Для signed-чисел можно применить те же рассуждения, оценка не изменится.
- Максимальное 64-битное число представляется строкой в 20 символов. Таким образом, на определение длины строки нужно 5 запросов, т.к. 25=32
- — ближайшая сверху точная степень двойки (на самом деле немного меньше, как будет показано ниже, но пока округлим в большую сторону).
- Дальше в зависимости от длины строки нужно потратить 3-4 запроса на каждую цифру (почему так — смотри ниже в разделе «Сужение диапазона поиска»). Длина строки равна ceil(log10(N))
- , где N
- — искомое число.
- Таким образом, общее количество запросов — 5+3,4∗(ceil(log10(N))).
Максимальное количество запросов для максимальной длины — 73. Банальный бинарный поиск на все 64 бита требует 64 запроса вне зависимости от размера числа.
Для улучшения алгоритма мы можем:
- Определить, сколько в числе битов (ln2(N)
- ). Возможные значения — от 1 до 64, то есть нам потребуется 6 запросов (26=64
- ).
- Дальше в зависимости от количества битов еще нужно столько запросов, сколько в числе битов. Битов в числе — ceil(log2(N))
- , то есть в сумме получается 6+ceil(log2(N)).
- Для сравнения двух вариантов уберем округление и приведем формулу оценки общего количества запросов к логарифму по основанию 2:
- 5+3,4∗log10(N)=5+3,4∗log2(N)log2(10)=5+3,43,33∗log2(N)
Видно, что разница формул в основном описывается дробью
3,43,33
, которая не сильно отличается от 1
, то есть приведенные алгоритмы имеют примерно одинаковую эффективность. Первый алгоритм удобно использовать, когда мы не знаем заранее тип колонки, — мы можем всегда все колонки конвертировать в текстовый тип и получать работающую атаку (правда, ценой небольшого удлинения запроса).
РАБОТА С ДИАПАЗОНАМИ ПОИСКА
В данном разделе рассмотрены различные подходы к эксплуатации слепых SQL-инъекций при использовании разных диапазонов поиска.
Сужение диапазона поиска
До этого мы говорили о том, что для определения одного символа требуется 7 запросов, за которые мы можем определить значение из диапазона 0x00-0x7f (алфавит объема 27
), что соответствует нижней (английской) половине таблицы ASCII. Идея ускорения состоит в том, что мы можем искать символы не среди всей нижней половины ASCII-таблицы, а среди какого‑то ее подмножества.
Давайте разберем пример, когда нам известно, что целевая строка состоит исключительно из цифр, и оценим скорость подбора.
Алфавит подбора имеет мощность 10. Для точных степеней 2 мы могли бы взять просто логарифм по основанию 2 от мощности алфавита. Однако 10 не является степенью 2, а значит, определить количество запросов для определения символа чуть сложнее:
- Первый запрос покажет, входит символ в множество
[0,1,2,3,4]или в[5,6,7,8,9]. - Второй запрос разобьет полученную группу из 5 элементов на группы из 2 и 3 элементов:
[0,1]и[2,3,4]для первого случая;[5,6]и[7,8,9]для второго случая.- Третий запрос найдет значение в случае, если целевой символ был в диапазонах
[0,1]и[5,6]. - Для диапазонов
[2,3,4]и[7,8,9]одним запросом мы можем сделать разделение на поддиапазоны из одного и двух символов: [2,3,4]разобьем на[2]и[3,4];[7,8,9]разобьем на[7]и[8,9].- Таким образом символы
[2]и[7]будут найдены третьим запросом. - Если целевой символ находится в
[3,4]или[8,9], то понадобится еще один (четвертый) запрос.
Получается, для 6 возможных значений мы делаем 3 запроса, а для оставшихся 4 значений — 4 запроса. Итого в среднем мы делаем 3-4 запроса на один символ. Это более чем в 2 раза лучше, чем полный бинарный поиск в диапазоне из возможных 128 значений.
Математическая оценка
Определить среднее количество запросов для символа из алфавита мощностью N можно по формуле
q=((N−N2)∗2∗(log2(N2)+1)+(N2∗2−N)∗log2(N2))/N
где N2
— ближайшая снизу к N полная степень числа 2: N2=2floor(ln2(N))
.
from math import log,floor
def questions(N):
pow2 = 2**floor(ln2(N))
return ((N-pow2)*2*(ln2(pow2)+1) + (pow2*2-N)*ln2(pow2))/N
def ln2(x):
return log(x)/log(2)
Функцию q
можно апроксимировать как log2(N)
, но реальное q
будет всегда чуть больше, чем log2(N)
для N, не являющихся точной степенью двойки.
Определение ошибок
Для дальнейших рассуждений разберем пример, в котором мы предполагаем, что целевой символ является маленькой английской буквой из диапазона a-z:
- Будем искать значение соответствующего ASCII-кода в диапазоне чисел
97-122. Серединой диапазона является число 109,5. - Определим, больше ASCII-код целевого символа, чем 109,5, или меньше:
(ascii(substr(target_col,5,1)) from target_table limit 2,1)>109- Если ASCII-код меньше, то целевой диапазон уменьшится до
97-109, если больше — до110-122. - Далее новый дипазон также бьется на две части и так далее, пока символ не будет определен.
Таким образом, среднее количество запросов получается q(26)=4,77.
Канареечные символы
Если наше изначальное предположение «целевым символом является маленькая английская буква» — неверное, то мы получим в результате бинарного поиска одно из граничных значений — a или z. Отличить такой случай от настоящих букв «a» или «z» без дополнительных запросов мы не сможем. Для решения этой проблемы мы можем добавить на обеих границах диапазона по символу‑канарейке — то есть искать целевое значение мы будем не в диапазоне 97-122, как в примере выше, а в диапазоне 96-123. Если в результате поиска будет получено канареечное значение 96 или 123, мы сможем понять, что изначальное предположение неверно.
Такая техника позволяет использовать диапазонный поиск в случае, когда мы с хорошей долей вероятности можем предположить об алфавите конкретного символа, но не уверены на 100%. При этом стоит помнить, что расширение диапазона канареечными символами приводит к увеличению среднего количество запросов на один символ: с q(26)=4,77
до q(28)=4,86.
Также необходимо отметить, что если символ отсутствовал в диапазоне поиска, то нам потребуется к уже потраченным запросам добавить:
- q(97)
- , если значение меньше 97;
- q(5)
- , если больше 122.
Если считать, что символы распределены равномерно, то в сумме получается
q(97)∗97102+q(5)∗5102+4,86=11,33
, что намного больше изначальных 7 запросов. То есть предположение о диапазоне должно иметь достаточно высокую вероятность, иначе попытка ускорения может обернуться потерей производительности.
Поиск в диапазонах с разрывами
Теперь рассмотрим поиск в наборе возможных значений, которые не образуют непрерывного диапазона в ASCII-таблице. Например, наша цель — шестнадцатеричная строка, набор значений [0-9A-F]. Для решения данной задачи можно предложить две техники:
- инъекция с помощью операторов
INиNOT IN; - поиск с игнорированием разрывов.
Инъекция с помощью операторов IN и NOT IN
Список допустимых ASCII-кодов в рассматриваемом случае: [48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 97, 98, 99, 100, 101, 102]. Мы можем разделить этот перечень пополам и спрашивать у СУБД, попадает ли искомый символ в подсписок. Условие тогда будет выглядеть примерно так:
(ascii(substr(target_col,5,1)) from target_table limit 2,1) in (48, 49, 50, 51, 52, 53, 54, 55)
Если условие выполнится, то целевое значение будет находится в наборе [48, 49, 50, 51, 52, 53, 54, 55]. Если нет — то в наборе [56, 57, 97, 98, 99, 100, 101, 102]. Далее, шаг за шагом разделяя полученные диапазоны пополам, мы получим целевое значение. На определение одного символа будет потрачено q(16)=4
запроса.
Cтоит отменить, что в данном случае присутствует та же проблема, что и для диапазонов: если мы не уверены в изначальном предположении об алфавите поиска, то ошибку мы не обнаружим. Для ее решения можно:
- добавить к алфавиту одно псевдозначение, которое будет соответствовать сразу всем символам, не вошедшим в алфавит;
- для поиска использовать исключительно конструкцию
NOT IN.
Пример:
- Рассмотрим случай, когда алфавит поиска состоит из трех значений
[1, 3, 5]. - Добавим к значениям
[1, 3, 5]псевдозначение N — получим[1, 3, 5, N]. - Сделаем запрос
(ascii(substr(target_col,5,1)) from target_table limit 2,1) NOT IN (1,3). Если получимFalse, то целевой символ либо 1, либо 3, и следующим запросом мы получим точный ответ. Если же мы получилиTrue, то ответ либо равен 5, либо мы ошиблись с диапазоном. - Сделаем точное сравнение с 5:
(ascii(substr(target_col,5,1)) from target_table limit 2,1) NOT IN (5). Если получилиTrue, значит, мы ошиблись в нашем изначальном предположении об алфавите.
Эта техника лучше, чем предложенные выше канареечные символы на краях диапазона, так как c использованием оператора NOT IN мы можем осуществлять бинарный поиск в диапазонах с разрывами, при этом для обнаружения ошибки нам придется увеличить размер алфавита всего на 1. К недостаткам этой техники можно отнести удлинение запроса в силу перечисления половины алфавита в параметре операторов IN и NOT IN.
Поиск с игнорированием разрывов
Еще одна возможность решить задачу поиска в диапазоне с разрывом [0-9A-F] — выполнить поиск с игнорированием разрывов в диапазоне:
- Разделим пополам диапазон
[48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 97, 98, 99, 100, 101, 102]. Граница диапазона будет проходить между символами55и56. - Сделаем запрос с помощью оператора сравнения:
(ascii(substr(target_col,5,1)) from target_table limit 2,1) > 55. Ответ позволяет выбрать одну из половин изначального диапазона.
Эту технику нужно применять, пока в диапазоне не останется ровно 1 символ. В результате нам также потребуется q(16)=4
запроса.
Данная техника может быть дополнена для выполнения поиска ошибок с помощью канареечных символов.
- Добавим к перечню значений, которые мы ищем, канареечные значения:
- одно меньше самого маленького — 47;
- одно больше самого большого — 103;
- одно в пропуске, например 58.
- Выполним поиск так же, как указано выше. Cписок возможных значений —
[47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 97, 98, 99, 100, 101, 102, 103]. - Найдем середину диапазона (
56) и выполним сравнение:(ascii(substr(target_col,5,1)) from target_table limit 2,1) > 56. - В результате выполнения запроса мы получим информацию о том, что целевое значение лежит в одном из двух наборов:
[47, 48, 49, 50, 51, 52, 53, 54, 55, 56];[57, 58, 97, 98, 99, 100, 101, 102, 103].- Выберем середину диапазона, отправим запрос, разделим набор на две части и так далее.
- В итоге мы либо получим значение из изначального диапазона поиска (оно и будет ответом), либо канареечные значения
47,103или58(любое из этих значений покажет, что целевого символа в диапазоне не было). Также мы получим информацию о том, целевой символ больше102, меньше48или лежит на отрезке59-96.
Если предполагаемый диапазон имеет более одного разрыва (пусть их r
), то количество канареечных символов возрастает: нужно использовать границы 2+r.
Использование диапазонов с большим количеством разрывов снижает потенциальную производительность за счет большего количества канареечных символов. Запросы в данном случае короче, чем те, которые применяются при использовании операторов IN и NOT IN. В случае ошибки мы получаем дополнительную информацию о том диапазоне, в котором лежит ошибочный символ — слева, справа или в одном из разрывов.
Подстройка диапазона поиска
Помимо жестко заданных диапазонов, мы можем модифицировать диапазон в процессе проведения атаки, то есть «на лету».
Идеи оптимизации
Если мы уже собрали в данной колонке несколько строк и все эти строки имеют определенный набор символов, то вероятно, что и следующие строки в этой колонке будут иметь тот же набор символов. Соответственно, мы можем динамически собрать диапазон используемых символов и в дальнейшем применять этот диапазон для поиска значений в этой колонке. Ошибки в предположении (например, если нам ни разу не встретился символ, который на самом деле может встречаться) можно нивелировать использованием канареечных символов.
Некоторые колонки могут иметь жестко заданные символы в определенных позициях. Например, GUID (пример — 6F9619FF-8B86-D011-B42D-00CF4FC964FF) имеет символ - (минус) на позициях [8, 13, 18, 23]. Мы можем проверить, что все символы на соответствующей позиции среди уже собранных записей имеют одинаковое значение и вместо бинарного поиска отправить один запрос для проверки этого символа.
Можно пойти и еще дальше и на основе имеющейся статистики по встречающимся символам собирать диапазоны так, чтобы поиск символов, которые встречаются чаще, требовал бы меньше запросов. Формальная постановка задачи — формирование алгоритма, минимизирующего число запросов для обнаружения символов на основе имеющегося вероятностного распределения символов. Оптимально решить такую задачу можно с помощью H-дерева, используемого в коде Хаффмана.
Действительно, задача сжатия аналогична нашей задаче: мы хотим находить часто встречающиеся символы за меньшее количество запросов (то есть потратить на них меньше битов), а алгоритм сжатия — представлять такие символы наименьшим количеством битов. Построение такого дерева требует однократного прохождения по всей собранной информации для сбора статистики. Само построение имеет сложность O(n∗log(n))
(где n
— размер алфавита), что не так уж много для алфавитов в нашей задаче.
Пусть мы собрали несколько строк и в них имеется следующая статистика распределения символов:
СИМВОЛСКОЛЬКО РАЗ ВСТРЕТИЛСЯВЕРОЯТНОСТЬa3447,2%b79,7%c57%d1216,7%e45,5%f1013,9%Для такой статистики можно построить следующее оптимальное H-дерево:
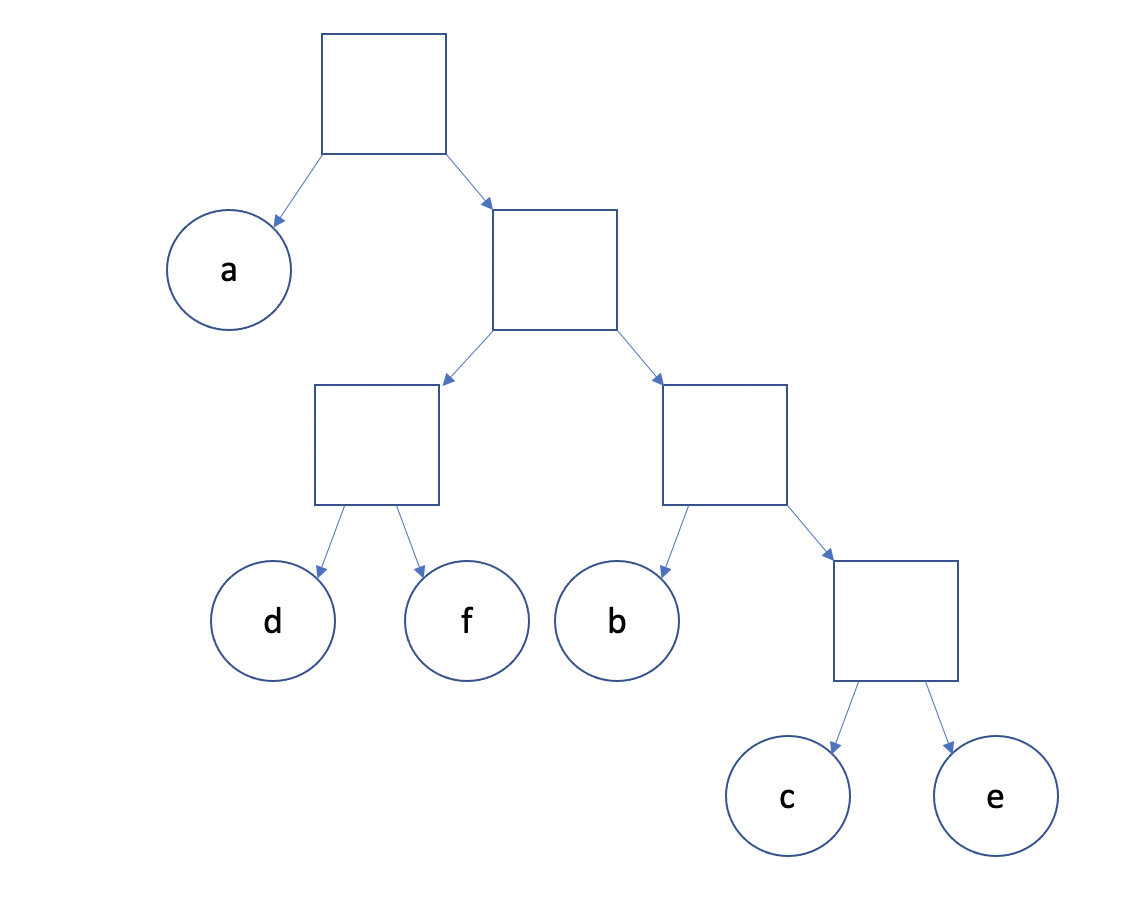
Для различных символов потребуется различное количество запросов:
- для символа
a— один запрос; - для
d,fиb— два запроса; - для
cиe— три запроса.
Матожидание числа запросов на один символ:
1∗(0,472)+2∗(0,167+0,139+0,097)+3∗(0,07+0,055)=1,653
При обычном поиске по диапазону оно составило бы q(6)=2,67.
H-дерево можно периодически перестраивать по мере появления новой статистики. Поиск в таком случае будет чаще требовать разрывов в диапазонах, поэтому в данном случае будет предпочтительно использовать технику с операторами IN и NOT IN.
Вывод: можно построить алгоритм автоматической подстройки диапазона поиска на основе имеющейся статистики, что позволит существенно поднять скорость поиска.
ДРУГИЕ ИДЕИ ОПТИМИЗАЦИИ
Соединение строк
Еще один алгоритм оптимизации основывается на идее объединения всего ответа в одну строку через разделители. Это позволяет определить длину строки один раз и сэкономить запросы, однако при этом каждый разделитель увеличивает количество символов, которые необходимо определить.
Идея алгоритма
- Для соединения колонок мы можем использовать операцию конкатенации соответствующей СУБД, ставя между ними редко используемый разделитель (например,
0x01). Строки (rows) мы также можем объединить с использованием специальных функции (group_concatдля MySQL,string_aggдля PostgreSQL). В качестве разделителя строк будем использовать тот же самый разделитель0x01. - Анализируя полученный ответ, мы сможем отличить начало новой строки (row), подсчитывая количество колонок. На определение длины строки мы потратим чуть больше запросов. Однако количество запросов примерно равно логарифму длины строки и, соответственно, растет медленнее, чем сумма запросов, которые мы потратили бы на определение длин каждой строки в отдельности.
- Также в данном случае мы можем не определять длину строки вовсе, а просто обнаруживать символы, пока они не кончатся, как описано в разделе «Определение количества row и длины строк». Однако тогда мы не сможем оценить, сколько времени займет получение данных, что, скорее всего, неприемлемо на практике.
- Количество запросов, которые будут потрачены на определение разделителей, зависит от используемого диапазона подбора. Разделитель сам по себе добавляется как один символ в диапазон. Суммарное количество разделителей равно количеству возвращаемых строк минус 1. Таким образом, можно сказать, что мы заменяем затраты на определение длин строк на затраты на определение разделителей.
- Если считать, что на определение длины строки в среднем тратится 7 запросов, как указано в разделе «Определение количества записей и длины строк», то это позволяет сэкономить 7−q(len(D))
- запросов на каждую строку (где D
- — диапазон поиска). Также мы теряем q(len(D))−q(len(D)−1)
- запросов на каждый символ, т.к. добавляем разделитель в диапазон.
- Использовать разные диапазоны для поиска в разных колонках мы можем лишь ограниченно — так как мы используем многопоточность и не можем заранее знать — перевалим мы через разделитель при подборе очередного символа и, соответственно, попадем в другую колонку или нет. Поэтому либо мы должны использовать широкие диапазоны, что увеличивает q(len(D))
- и снижает выигрыш от отсутствия необходимости определения длин строк, либо мы можем использовать соответствующие текущей колонке диапазоны и получать дополнительное количество ошибок — попаданий в канареечные символы с последующим повторным поиском.
Вывод: данная техника применима только в определенных случаях, например когда все целевые колонки имеют узкий диапазон.
Работа с UNICODE
В случае, когда в искомом тексте встречаются символы, отсутствующие в стандартной английской ASCII-таблице, СУБД применяют для хранения Unicode. Причем в некоторых СУБД (например, MySQL) по умолчанию применяется UTF-8, а в других (например, PostgreSQL) — UTF-16. В обоих случаях преобразование символа с помощью функции ASCII/UNICODE приведет к получению значения больше 128. Получение значения больше 128 и будет для нас триггером того, что в строке встречаются Unicode-символы.
Unicode-символы имеют характерный вид для различных языков. Например, русские буквы в UTF-8 в качестве первого байта имеют 0xDO или 0xD1. Если мы работаем с UTF-8, то мы можем предположить, что после одного UTF-8 символа с русской буквой будет идти еще один. Тогда первый байт этого символа мы можем эффективно обнаружить, используя алфавит из двух значений [0xD0,0xD1], а для второго байта мы можем ограничить поиск только значениями, которые соответствуют русским буквам.
Однако такой подход не очень хорошо совместим с многопоточным поиском: вероятность того, что символ, идущий через N
символов после текущего, также является русским символом UTF-8, падает с ростом N.
В слове на русском языке в UTF-8 каждый второй символ будет 0xD0 или 0xD1, но после конца слова, скорее всего, будет стоять однобайтовый символ пробела или знака препинания. Это снижает вероятность того, что через четное число символов после встреченного 0xD0 также будет 0xD0 или 0xD1.
Вывод: при работе с Unicode возможным решением является использование одного потока на каждую строку.
Сжатие данных
Ряд СУБД поддерживают встроенные функции сжатия (например, COMPRESS для MySQL и UTL_COMPRESS.LZ_COMPRESS для Oracle). Соответственно, их применение позволяет уменьшить количество символов, которые нам требуется получить. При этом нам не нужно делать предположения об используемом алфавите: результат сжатия — BLOB. Мы будем использовать полный диапазон из 256 значений.
Нужно учитывать, что функции сжатия добавляют дополнительные данные в начало сжатого BLOB: размер изначальной строки и таблицу обратного преобразования. Таким образом, эффект имеется только для длинных строк, а для совсем коротких строк эффект вообще может быть отрицательным:
SELECT LENGTH(COMPRESS('123'))
>> 15
Вывод: подобную технику имеет смысл применять совместно с техникой соединения строк. Объединенная строка будет длинной, и алгоритмы сжатия смогут сжать ее достаточно эффективно. Однако мы будем заставлять СУБД выполнять процедуру сжатия длинной строки при каждом запросе, чем можем увеличить время выполнения каждого запроса.
А ЧТО ТАМ SQLMAP?
Работа с потоками
Sqlmap не использует многопоточность при определении количества записей или длин строк. Одновременно он ищет только символы одной строки.
Определение длины строки
Sqlmap ищет длину строки, если используется несколько потоков. Если используется один поток, то он считает, что строка закончилась, как только обнаружен первый символ 0x00.
Поиск символов
При поиске символов sqlmap использует следующую технику:
- Первый символ ищется полным перебором из 128 символов (7 запросов).
- Далее выбирается символ, с которого начнется следующий поиск на основании предыдущего обнаруженного символа:
- если это цифра, то sqlmap выбирает
48(ASCII-код минимального символа, цифры0); - если строчная буква, то он выбирает
96(кодa); - если заглавная буква, то
64(кодA). - Далее происходит сравнение с этим определенным числом и используется обычный бинарный поиск в оставшемся диапазоне. То есть если предыдущий символ — буква, то делается сначала сравнение с
48, а затем, если искомое значение больше, делается поиск в диапазоне48-127.
Единственное исключение: если оказывается, что слева от текущего сравниваемого символа нет ожидаемых, то он сразу переходит к сравнению с 1. Если сравнение с 1 показывает, что целевой символ меньше, то sqlmap считает, что нашел конец строки, и заканчивает поиск.
К плюсам данного подхода можно отнести эффективное обнаружение конца строки, особенно если последний символ строки — число. Тогда конец строки будет определен всего за 3 запроса. Но эта техника имеет и недостаток — низкая эффективность поиска в части случаев.
Предположим, что предыдущий символ был цифрой. Тогда первое сравнение делается с 48, и если следующий символ существует и больше 48 (а это наиболее вероятная ситуация), то на его определение будет использован диапазон из 128−48=80
символов, то есть q(80)=6,4
запросов. При этом один запрос уже будет сделан для сравнения с 48, так что суммарно sqlmap потратит 7,4 запроса (другими словами, появляется вероятность, что он потратит 8 запросов). При этом, если бы sqlmap делал полный бинарный поиск, то потратил бы ровно 7 и никак не больше.
Выбор диапазона символов
У sqlmap есть параметр --charset, с помощью которого можно задать диапазон символов, среди которых будет проводится бинарный поиск.
Unicode
Sqlmap умеет автоматически обнаруживать неоднобайтовые символы, однако работа с ними крайне медленная. В моем эксперименте на поиск одной русской буквы в среднем уходило 34 запроса.
Другие рассмотренные варианты оптимизации в sqlmap не реализованы (по крайней мере, я их не обнаружил).
ВЫВОДЫ
В этой статье я привел теоретический обзор основных способов оптимизации эксплуатации Blind SQL-инъекций. Какие‑то из них более эффективны, какие‑то менее, но я попытался привести наиболее полный перечень. Если у тебя есть другие идеи и техники оптимизации — пиши мне в телеграм @sorokinpf, обсудим!
Постепенно я планирую реализовать некоторые из описанных способов в своем фреймворке для эксплуатации Blind SQL-инъекций — sqli_blinder (да, с фантазией у меня так себе). На данный момент фреймворк реализует банальный бинарный поиск, поддерживает работу с SQLite, MSSQL, Oracle, MySQL и PostgreSQL. Для работы с ним необходимо написать одну функцию на python, которая определит, куда фреймворку подставлять запросы и как анализировать ответы.
Читайте ещё больше платных статей бесплатно: https://t.me/hacker_frei