Хакер - Прослушка VoIP. Как PRISM и BULLRUN извлекают информацию из голосового потока
hacker_frei

Содержание статьи
- Что злоумышленник может извлечь из зашифрованного аудиопотока
- Атака на VoIP по обходным каналам
- Несколько слов о DTW-алгоритме
- Принцип действия HMM-автоматов
- Принцип действия PHMM-автоматов
- От теории к практике: распознавание языка, на котором идет разговор
- Прослушивание шифрованного аудиопотока Skype
- А если отключить VBR-режим?
- Заключение
Такие вопросы стали в особенности злободневными после откровений Сноудена, рассказавшего миру о тотальной прослушке, которую правительственные спецслужбы вроде АНБ (Агентство национальной безопасности) и ЦПС (Центр правительственной связи) ведут при помощи шпионского софта PRISM и BULLRUN — этому софту, как оказывается, под силу даже шифрованные переговоры.
Каким же образом PRISM, BULLRUN и другой, им подобный софт извлекает информацию из голосового потока, передаваемого по зашифрованным каналам?
Для того чтобы найти ответ на этот вопрос, нужно сначала разобраться, как в VoIP передается голосовой трафик. Канал передачи данных в VoIP-системах, как правило, реализуется поверх UDP-протокола и наиболее часто работает по протоколу SRTP (Secure Real-time Transport Protocol — протокол защищенной передачи данных в режиме реального времени), который поддерживает упаковку (посредством аудиокодеков) и шифрование аудиопотока. При этом шифрованный поток, который получается на выходе, имеет тот же самый размер, что и входной аудиопоток. Как будет показано ниже, подобные, казалось бы, незначительные утечки информации можно использовать для прослушивания «шифрованных» VoIP-переговоров.
На чём основана возможность прослушивать шифрованный голосовой трафик?
- На низкой энтропии данных, возникающей из-за оптимизации сжатия
- На слабых ключах шифрования
- На особенностях протокола UDP
Что злоумышленник может извлечь из зашифрованного аудиопотока
Большинство из тех аудиокодеков, которые применяются в VoIP-системах, основаны на CELP-алгоритме (Code-Excited Linear Prediction — кодовое линейное предсказание), функциональные блоки которого представлены на рисунке ниже. Чтобы добиться более высокого качества звука без увеличения нагрузки на канал передачи данных, VoIP-софт обычно использует аудиокодеки в VBR-режиме (Variable bit-rate — аудиопоток с переменным битрейтом). По такому принципу работает, например, аудиокодек Speex.
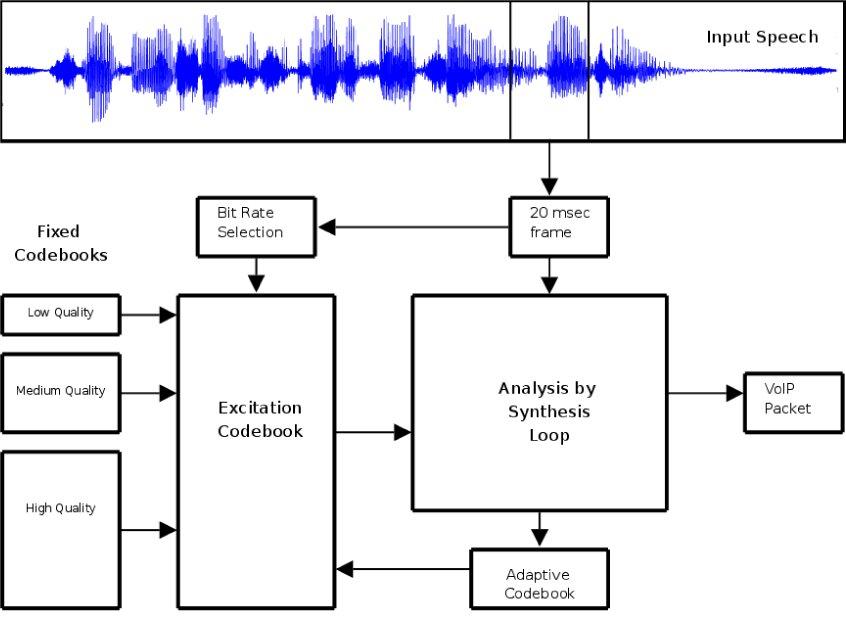 Функциональные блоки алгоритма CELP
Функциональные блоки алгоритма CELPК чему это приводит в плане конфиденциальности? Простой пример. Speex, работая в VBR-режиме, упаковывает шипящие согласные меньшим битрейтом, чем гласные, и более того — даже определенные гласные и согласные звуки упаковывает специфическим для них битрейтом. График на рисунке ниже показывает распределение длин пакетов для фразы, в которой есть шипящие согласные: Speed skaters sprint to the finish. Глубокие впадины графика приходятся именно на шипящие фрагменты этой фразы. На рисунке представлена (источник) динамика входного аудиопотока, битрейта и размера выходных (зашифрованных) пакетов, наложенная на общую шкалу времени; поразительное сходство второго и третьего графиков можно видеть невооруженным взглядом.
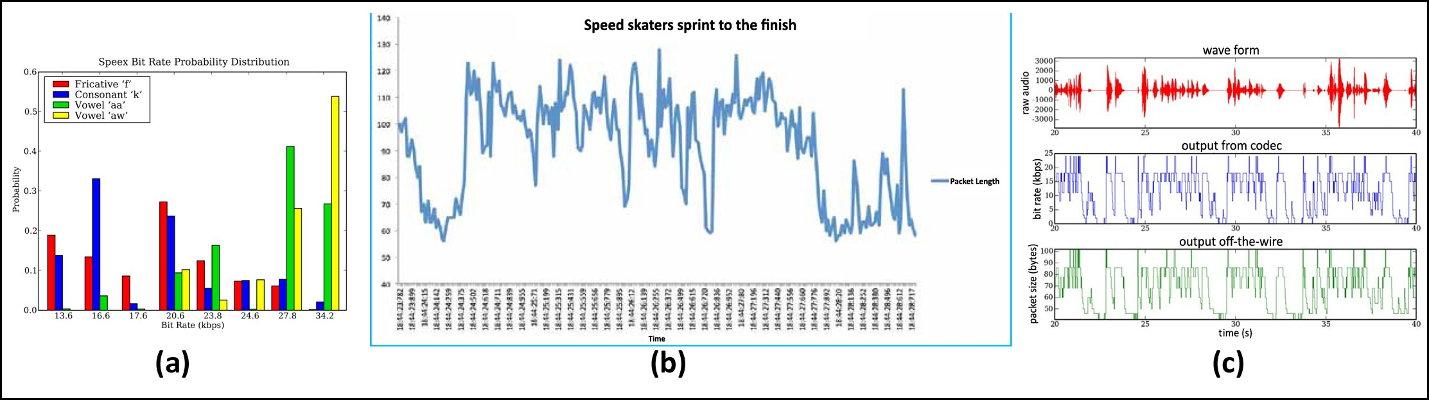 Как шипящие звуки влияют на размер пакетов
Как шипящие звуки влияют на размер пакетовПлюс, если на рисунок посмотреть через призму математического аппарата цифровой обработки сигналов (который используется в задачах распознавания речи), вроде PHMM-автомата (Profile Hidden Markov Models — расширенный вариант скрытой марковской модели), то можно будет увидеть намного больше, чем просто отличие гласных звуков от согласных. В том числе идентифицировать пол, возраст, язык и эмоции говорящего.
Атака на VoIP по обходным каналам
PHMM-автомат очень хорошо справляется с обработкой числовых цепочек, с их сравнением между собой и нахождением закономерностей между ними. Именно поэтому PHMM-автомат широко используется в решении задач распознавания речи.
Кроме того, PHMM-автомат оказывается полезным и для прослушивания зашифрованного аудиопотока. Но не напрямую, а по обходным каналам. Иначе говоря, PHMM-автомат не может прямо ответить на вопрос: «Какая фраза содержится в этой цепочке шифрованных аудиопакетов?», но может с большой точностью ответить на вопрос: «Содержится ли такая-то фраза в таком-то месте такого-то зашифрованного аудиопотока?»
Таким образом, PHMM-автомат может распознавать только те фразы, на которые его изначально натренировали. Однако современные технологии глубокого обучения настолько могущественны, что способны натренировать PHMM-автомат до такой степени, что для него фактически стирается грань между двумя озвученными чуть выше вопросами. Чтобы оценить всю мощь данного подхода, нужно слегка погрузиться в матчасть.
В чем основное отличие атаки по обходным каналам от взлома ключа шифрования?
- Для неё требуется больше ресурсов
- Она выполняется по типу MITM
- Полученная расшифровка всегда носит вероятностный характер
Несколько слов о DTW-алгоритме
DTW-алгоритм (Dynamic Time Warping — динамическая трансформация временной шкалы) до недавнего времени широко использовался при решении задач идентификации говорящего и распознавания речи. Он способен находить сходства между двумя числовыми цепочками, сгенерированными по одному и тому же закону, — даже когда эти цепочки генерируются с разной скоростью и располагаются в разных местах шкалы времени. Это именно то, что происходит при оцифровке аудиопотока. Например, говорящий может произнести одну и ту же фразу с одним и тем же акцентом, но при этом быстрее или медленнее, с разным фоновым шумом. Это не помешает DTW-алгоритму найти сходства между первым и вторым вариантом. Чтобы проиллюстрировать на примере, рассмотрим две целочисленные цепочки:
0 0 0 4 7 14 26 23 8 3 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 5 6 13 25 24 9 4 2 0 0 0 0 0
Если сравнивать эти две цепочки «в лоб», то они, очевидно, сильно отличаются друг от друга. Однако если мы сравним их характеристики, то увидим, что цепочки определенно имеют некоторое сходство: обе они состоят из восьми целых чисел, обе имеют схожее пиковое значение (25–26). «Лобовое» сравнение, начинающееся от их точек входа, игнорирует эти важные характеристики. Но DTW-алгоритм, сравнивая две цепочки, учитывает их и другие показатели. Однако мы не будем сильно акцентироваться на DTW-алгоритме, поскольку на сегодняшний день есть более эффективная альтернатива — PHMM-автоматы.
Экспериментально было установлено, что PHMM-автоматы «опознают» фразы из зашифрованного аудиопотока с 90%-й точностью, тогда как DTW-алгоритм дает только 80%-ю гарантию. Поэтому DTW-алгоритм (который в годы своего расцвета был популярным инструментом в решении задач распознавания речи) упоминаем лишь для того, чтобы показать, насколько лучше в сравнении с ним PHMM-автоматы (в частности, при распознавании шифрованного аудиопотока). Конечно, DTW-алгоритм обучается значительно быстрее, чем PHMM-автоматы. Это его преимущество неоспоримо. Однако при современных вычислительных мощностях оно не будет принципиальным.
Принцип действия HMM-автоматов
HMM (просто HMM, а не PHMM) представляет собой инструмент статистического моделирования, который генерирует числовые цепочки, следуя системе, заданной детерминированным конечным автоматом, каждая из переходных функций которого представляет собой так называемый марковский процесс. Работа этого автомата всегда начинается с состояния B (begin) и заканчивается состоянием E (end). Выбор очередного состояния, в которое будет выполнен переход из текущего, делается в соответствии с переходной функцией текущего состояния. По мере продвижения между состояниями HMM-автомат на каждом шаге выдает по одному числу, из которых формируется выходная цепочка чисел. Когда HMM-автомат оказывается в состоянии E, формирование цепочки заканчивается.
При помощи HMM-автомата можно находить закономерности в цепочках, которые внешне выглядят случайными. Например, здесь это достоинство HMM-автомата используется для нахождения закономерности между цепочкой длин пакетов и целевой фразой, наличие которой мы проверяем в зашифрованном VoIP-потоке.
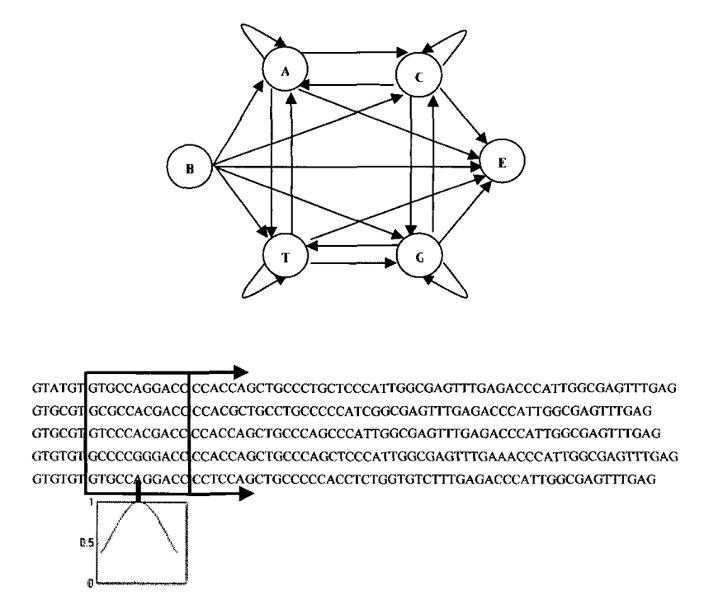 Пример HMM-автомата
Пример HMM-автоматаХотя существует большое количество возможных путей, по которым HMM-автомат может пройти из точки B в точку E (в нашем случае при упаковке отдельно взятого аудиофрагмента), все же для каждого конкретного примера (даже для такого случайного, как марковский процесс) есть один-единственный лучший путь, одна-единственная лучшая цепочка. Она же будет и наиболее вероятной претенденткой, которую, скорее всего, выберет аудиокодек при упаковке соответствующего аудиофрагмента (ведь ее уникальность выражается в том числе и в том, что она лучше других поддается упаковке). Такие «лучшие цепочки» могут быть найдены при помощи алгоритма Витерби (как это, например, сделано здесь).
Кроме того, в задачах распознавания речи (в том числе из зашифрованного потока данных, как в нашем случае) также полезно уметь вычислять, насколько вероятно, что выбранная нами цепочка будет сгенерирована HMM-автоматом. Лаконичное решение данной задачи приведено здесь; оно опирается на алгоритм «вперед-назад» и алгоритм Баума — Велша.
Вот здесь на основе HMM-автомата разработан метод идентификации языка, на котором идет разговор, с точностью в 66%. Но такая низкая точность не очень впечатляет, поэтому есть более продвинутая модификация HMM-автомата — PHMM, которая вытягивает из шифрованного аудиопотока намного больше закономерностей. Например, вот здесь подробно описано, как при помощи PHMM-автомата идентифицировать в зашифрованном трафике слова и фразы (а эта задача будет посложнее, чем просто идентификация языка, на котором идет разговор) с точностью до 90%.
Принцип действия PHMM-автоматов
PHMM — это усовершенствованная модификация HMM-автомата, в которой, помимо состояний «соответствия» (квадраты с буквой M), также присутствуют состояния «вставки» (ромбы с буквой I) и «удаления» (круги с буквой D). Благодаря этим двум новым состояниям PHMM-автоматы, в отличие HMM-автоматов, способны распознать гипотетическую цепочку A-B-C-D, даже если она присутствует не полностью (например, A-B-D) или в нее произведена вставка (например, A-B-X-C-D). В решении задачи распознавания зашифрованного аудиопотока эти два нововведения PHMM-автомата в особенности полезны. Потому что выходные данные аудиокодека редко совпадают, даже когда аудиовходы очень похожи (когда, например, один и тот же человек произносит одну и ту же фразу). Таким образом, простейшая модель PHMM-автомата состоит из трех взаимосвязанных цепочек состояний («соответствия», «вставки» и «удаления»), которые описывают ожидаемые длины сетевых пакетов в каждой позиции цепочки (зашифрованных пакетов VoIP-трафика для выбранной фразы).
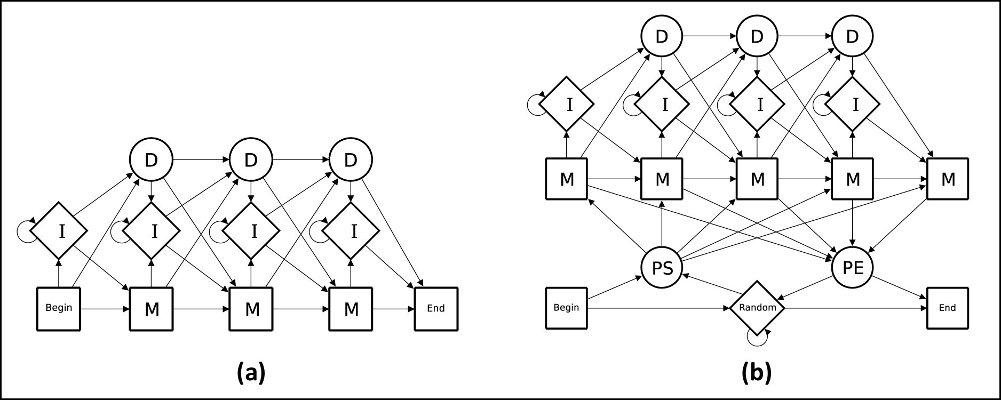 Пример PHMM-автомата
Пример PHMM-автоматаОднако, поскольку в зашифрованном аудиопотоке сетевые пакеты, по которым расфасована целевая фраза, как правило, окружены другими сетевыми пакетами (остальной частью разговора), нам потребуется еще более продвинутый PHMM-автомат. Такой, который сможет изолировать целевую фразу от других, окружающих ее звуков. Вот здесь для этого к исходному PHMM-автомату добавляют пять новых состояний. Наиболее важное из этих добавленных пяти состояний — «случайное» (ромб со словом Random). PHMM-автомат (после завершения стадии обучения) переходит в это состояние, когда к нему на вход попадают те пакеты, которые не являются частью интересующей нас фразы. Состояния PS (Profile Start) и PE (Profile End) обеспечивают переход между случайным состоянием и профильной частью модели. Такая улучшенная модификация PHMM-автомата способна распознавать даже те фразы, которых автомат «не слышал» на этапе обучения.
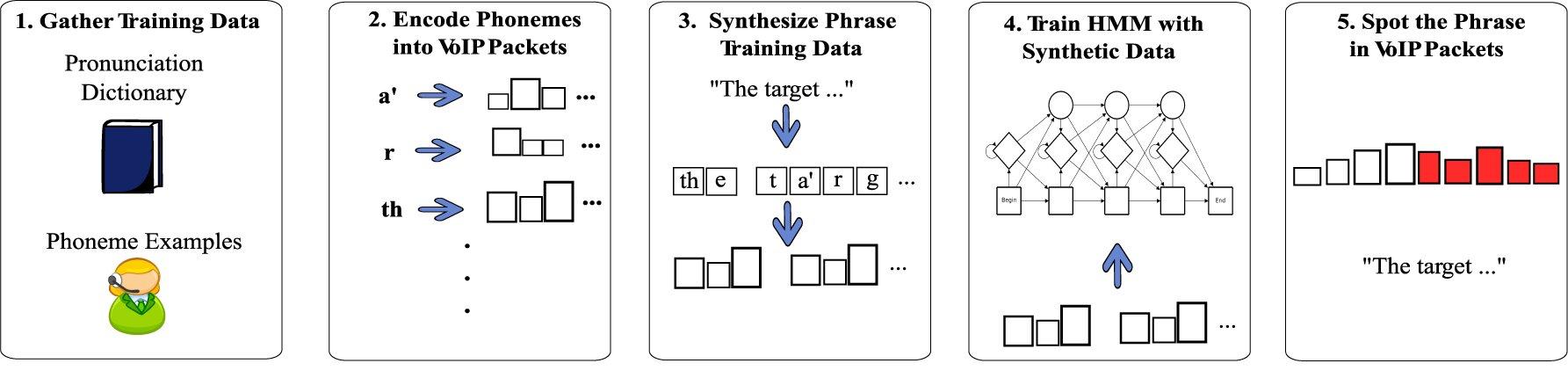 PHMM-автомат решает задачу распознавания шифрованного аудиопотока
PHMM-автомат решает задачу распознавания шифрованного аудиопотокаУ кого из российских операторов VoIP-телефонии самое слабое шифрование?
- Ростелеком
- Манго Телеком
- Zadarma
- У всех одинаково хреновое
От теории к практике: распознавание языка, на котором идет разговор
Вот здесь представлена экспериментальная установка на основе PHMM-автомата, при помощи которой были проанализированы шифрованные аудиопотоки с речью 2000 носителей языка из 20 разных языковых групп. После завершения тренировочного процесса PHMM-автомат идентифицировал язык разговора с точностью от 60 до 90%: для 14 из 20 языков точность идентификации превысила 90%, для остальных — 60%.
Экспериментальная установка, представленная на рисунке ниже, включает в себя два ПК под управлением Linux с опенсорсным софтом VoIP. Одна из машин работает как сервер и слушает в сети SIP-вызовы. После получения вызова сервер автоматически отвечает абоненту, инициализируя речевой канал в режим Speex over RTP. Здесь следует упомянуть, что канал управления в VoIP-системах, как правило, реализуется поверх TCP-протокола и либо работает по какому-то из общедоступных протоколов с открытой архитектурой (SIP, XMPP, H.323), либо имеет закрытую архитектуру, специфичную для конкретного приложения (как в Skype, например).
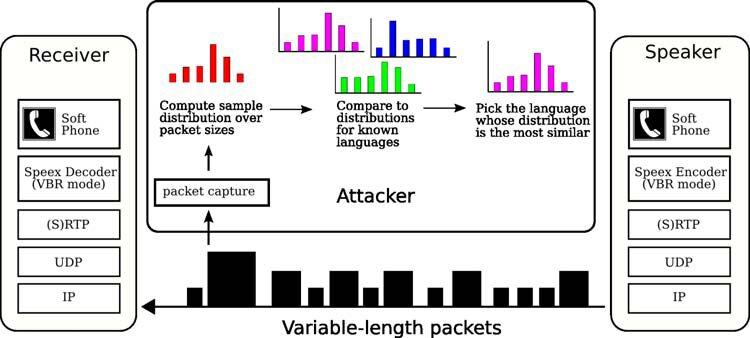 Экспериментальная установка для работы с PHMM-автоматом
Экспериментальная установка для работы с PHMM-автоматомКогда речевой канал инициализирован, сервер воспроизводит файл вызывающему абоненту, а затем завершает SIP-соединение. Абонент, который является еще одной машиной в нашей локальной сети, делает SIP-вызов серверу и затем при помощи сниффера «слушает» файл, который проигрывается сервером: прослушивает цепочку сетевых пакетов с шифрованным аудиотрафиком, поступающих от сервера. Далее абонент либо тренирует PHMM-автомат на идентификацию языка разговора (используя описанный в предыдущих разделах математический аппарат), либо «спрашивает» у PHMM-автомата, на каком языке идет разговор. Как уже упоминалось, данная экспериментальная установка обеспечивает точность идентификации языка до 90%.
Прослушивание шифрованного аудиопотока Skype
Здесь продемонстрировано, как при помощи PHMM-автомата решать еще более сложную задачу: распознавать шифрованный аудиопоток, генерируемый программой Skype (которая использует аудиокодек Opus/NGC в VBR-режиме и 256-битное AES-шифрование). В этой разработке используется экспериментальная установка вроде той, что представлена на рисунке выше, но только со Skype’овским кодеком Opus.
Для обучения своего PHMM-автомата исследователи воспользовались такой последовательностью шагов:
- Сначала собрали набор саундтреков, включающих все интересующие их фразы.
- Затем установили сниффер сетевых пакетов и инициировали голосовую беседу между двумя учетными записями Skype (это привело к генерации шифрованного UDP-трафика между двумя машинами, в режиме P2P).
- Затем проигрывали каждый из собранных саундтреков в Skype-сеансе, используя медиаплеер, с пятисекундными интервалами молчания между треками.
- Тем временем пакетный сниффер был настроен для регистрации всего трафика, поступающего на вторую машину экспериментальной установки.
После сбора всех тренировочных данных цепочки длин UDP-пакетов были извлечены при помощи автоматического парсера для PCAP-файлов. Полученные цепочки, состоящие из длин пакетов полезной нагрузки, затем использовались для тренировки PHMM-модели с использованием алгоритма Баума — Велша.
А если отключить VBR-режим?
Казалось бы, проблему подобных утечек можно решить, переведя аудиокодеки в режим постоянного битрейта (хотя какое же это решение — пропускная способность от этого резко снижается), но даже в этом случае безопасность шифрованного аудиопотока все еще оставляет желать лучшего. Ведь эксплуатация длин пакетов VBR-трафика — это лишь один из примеров атаки по обходным каналам. Но есть и другие примеры атак, например отслеживание пауз между словами.
Задача, конечно, нетривиальная, но вполне решаемая. Почему нетривиальная? Потому что в Skype, например в целях согласования работы UDP-протокола и NAT (network address translation — преобразование сетевых адресов), а также для повышения качества передаваемого голоса, передача сетевых пакетов не останавливается, даже когда в разговоре возникают паузы. Это усложняет задачу выявления пауз в речи.
Однако вот здесь разработан алгоритм адаптивного порогового значения, позволяющий отличать тишину от речи с точностью более 80%; предложенный метод основан на том факте, что речевая активность сильно коррелирует с размером зашифрованных пакетов: больше информации кодируется в голосовом пакете, когда пользователь говорит, чем во время молчания пользователя. А вот здесь (с акцентом на Google Talk, Lella и Bettati) говорящий идентифицируется, даже когда через размер пакетов никакая утечка не идет (даже когда VBR-режим отключен). Здесь исследователи опираются на измерение временных интервалов между приемами пакетов. Описанный метод опирается на фазы молчания, которые кодируются в более мелкие пакеты, с более длинными временными интервалами — чтобы отделять слова друг от друга.
Заключение
Как показывает практика, даже самая современная криптография неспособна защитить шифрованные VoIP-коммуникации от прослушивания, в том числе если эта криптография реализована надлежащим образом — что уже само по себе маловероятно. Стоит также отметить, что в данной статье подробно разобрана лишь одна математическая модель цифровой обработки сигналов (PHMM-автоматы), которая оказывается полезной при распознавании шифрованного аудиопотока (в таком шпионском софте правительственных спецслужб, как PRISM и BULLRUN). Но таких математических моделей существуют десятки и сотни. Так что если хочешь идти в ногу со временем — смотри на мир сквозь призму высшей математики.
Насколько далеко продвинулись системы прослушки VoIP-трафика?
- Нейросети спецслужб расшифровывают его на лету
- Можно прослушивать только отдельных абонентов, и это требует дополнительных действий
- Можно получить только общие данные (язык общения и типовые фразы)

INFO
Не забывай о критическом мышлении. Попробуй поговорить с голосовым вводом Google, но не старайся произносить фразы медленно и понятно. Говори как обычно. Включи автоматические субтитры в Youtube. Как тебе нравится качество распознавания исходно ничем не измененной голосовой информации?
Логичный вывод: со всеми перечисленными алгоритмами в плане распознавания речи все значительно хуже.
Читайте ещё больше платных статей бесплатно: https://t.me/hacker_frei